S.O.D. COBRA
Doinício da década de 60 até o começo dos anos 70, era enorme a insatisfação
com a situação brasileira no setor tecnológico. Nessa época, todos os
computadores no país era importados. No mesmo período, a Marinha comprou
fragatas inglesas comandadas por computador. O almirantado espantou-se com o
alto preço dos computadores em embarcações de combate com artilharia
eletrônica. Um grupo de oficiais conseguiram que parte do equipamento
passasse a ser fabricado por empresas brasileiras, reivindicando a criação de
uma indústria de eletrônica digital.
Em 18
de julho de 1974, a E.E. Eletrônica, o BNDE e a inglesa Ferranti
associaram-se para formar a COBRA - Computadores e Sistemas Brasileiros Ltda,
empresa cuja história se liga estreitamente à política de informática no
Brasil, foi a primeira empresa a desenvolver, produzir e comercializar
tecnologia genuinamente brasileira na área de informática.
Através de parcerias com a inglesa Ferranti e a
americana Sycor Inc. a Cobra acumulou conhecimento técnico-industrial. Do
início, quando
tudo
era novo e precisava ser desvendado, passou-se rapidamente ao desenvolvimento
de tecnologia e geração de seus próprios produtos.
Percebendo
a impossibilidade de competir com as gigantes estrangeiras na produção de
equipamentos de grande porte, a indústria nacional procurava um espaço que
permitisse seu desenvolvimento e auto-suficiência. A escolha do setor de
mínis e micros prendia-se a uma razão muito forte. Ao contrário dos grandes
computadores, o componente eletrônico principal desses equipamentos eram os
chips, facilmente comprados no exterior.
O Cobra 530, lançado no início da década de 80,
foi o primeiro computador totalmente projetado, desenvolvido e
industrializado no Brasil. Nessa época foram lançados os modelos da mesma
linha do C-530, como o C-520, C-540, C-480 e C-580, até chegar a linha X. Também
foram lançados os primeiros microcomputadores de 8 bits - o Cobra 300, Cobra
305 e o Cobra 210, além de terminais remotos. Nessa fase, uma série de sistemas
operacionais como o SOM, SOD, SPM e SOX (compatível com o Unix), e várias
linguagens como LPS, LTD, Cobol e Mumps foram criadas. Em 1987, a Cobra havia
lançado o XPC, o seu compatível PC-XT.
Na
segunda metade da década de 80, o controle de preços e o aumento das despesas
com os sucessivos planos econômicos descapitalizaram as empresas. Além disso,
com o fim da reserva de mercado da informática, trouxe as gigantes mundiais
do setor de informática. Foi um período em que muitas empresas nacionais
sucumbiram. A Cobra buscou novos caminhos e tornou-se integradora de soluções
tecnológicas e prestadora de serviços.
No início da década de 90, a Cobra se afinou à
tendência mundial de parcerias, dentre as quais a Sun Microsystems, IBM,
Cisco Systems, Microsoft, Oracle e SCO. Por essa época, o Banco do Brasil
passou a acionista majoritário da Cobra. No final dos anos 90, entrou firme e
forte no mercado de serviços para a área bancária.
|
Equipamentos
fabricados pela Cobra
|
|
|
Ano
|
Equipamento
|
Linha
|
Descrição
|
|
|
|
Cobra
700
|
Minicomputador
|
Primeiro
computador lançado pela Cobra, de tecnologia importada, era baseado no
Argus 700 da inglesa Ferranti.
|
|
|
1977
|
Cobra
400
|
Minicomputador
|
Os
primeiros Cobra 400 eram o modelo Sycor 440 importados da empresa americana
Sycor, pouco tempo depois a Cobra desenvolveu o Cobra 400 II. O Cobra 400
era um minicomputador baseado em microprocessadores 8080, da Intel.
|
|
|
1979
|
TD
200
|
Terminal
|
Terminal
inteligente de entrada de dados. Tinha 32 kB de RAM e duas unidades de
disquete de 8 pol., densidade simples, e era baseado no microprocessador
Intel 8080, de 8 bits.
|
|
|
1979
|
Cobra
300
|
Microcomputador
|
Originário
do TD 200, era um equipamento monoposto autônomo, memória RAM de 48 KB e
disquete de densidade dupla, era baseado no microprocessador Intel 8080, de
8 bits.
|
|
|
1980
|
Cobra
530
|
Minicomputador
de 16 bits
|
Primeiro
computador desse porte totalmente projetado, desenvolvido e industrializado
no Brasil.
|
|
|
1981
|
Cobra
305
|
Microcomputador
|
Um
modelo mais avançado que sucedeu o Cobra 300, a memória RAM era de 64 KB e
disquete de dupla face com 1 MB, era baseado no microprocessador Z 80A da
Zilog, de 8 bits.
|
|
|
1982
|
Cobra
520
|
Minicomputador
de 16 bits
|
Era
uma versão reduzida do Cobra 530.
|
|
|
1983
|
Cobra
540
|
Minicomputador
de 16 bits
|
|
|
|
1983
|
Cobra
210
|
Microcomputador
|
Os
programas aplicativos desenvolvidos para o Cobra 300 e Cobra 305 podiam ser
utilizado pelo Cobra 210, tinha 64 KB de RAM e era baseado no
microprocessador Z 80B, aceitava disco rígido Winchester de 5 a 10 MB.
|
|
|
|
Cobra
480
|
Supermicro/Mini
de 16 bits
|
|
|
|
|
Cobra
580
|
Minicomputador
de 16 bits
|
Era
uma versão reduzida do Cobra 540.
|
|
|
|
Cobra
1000
|
Supermini
|
Computador
fabricado sob licença da americana Data General.
|
|
|
|
X-10
|
Minicomputador
de 32 bits
|
Baseado
no processador Motorola 68010.
|
|
|
|
X-20
|
Minicomputador
de 32 bits
|
Baseado
no processador Motorola 68020.
|
|
|
|
X-30
|
Minicomputador
de 32 bits
|
Baseado
no processador Motorola 68030.
|
|
|
|
X-3030
|
Minicomputador
de 32 bits
|
Baseado
no processador Motorola 68030.
|
|
|
|
X PC
|
Microcomputador
|
Primeiro
microcomputador compatível com IBM PC/XT.
|
|
|
|
X
386S
|
Microcomputador
|
Baseado
no microprocessador Intel 80386.
|
|
|
|
MP
486 EISA
|
Microcomputador
|
Microcomputador
Medidata comercializado pela Cobra, baseado no microprocessador Intel
80486.
|
|
|
|
MP
486XM
|
Microcomputador
|
Baseado
no microprocessador Intel 80486 DX2.
|
|
|
|
|
|
|
|
|
|
|
O Cobra 530, lançado no início da década de 80, foi o primeiro computador
totalmente projetado, desenvolvido e industrializado no Brasil. Nessa época
foram lançados os modelos da mesma linha do C-530, como o C-520, C-540, C-480
e C-580, até chegar a linha X. Também foram lançados os primeiros
microcomputadores de 8 bits - o Cobra 300, Cobra 305 e o Cobra 210, além de
terminais remotos. Nessa fase, uma série de sistemas operacionais como o SOM,
SOD, SPM e SOX (compatível com o Unix), e várias linguagens como LPS, LTD,
Cobol e Mumps foram criadas. Em 1987, a Cobra havia lançado o XPC, o seu
compatível PC-XT.
Na segunda metade da década de 80, o controle de preços e o aumento
das despesas com os sucessivos planos econômicos descapitalizaram as
empresas. Além disso, com o fim da reserva de mercado da informática, trouxe
as gigantes mundiais do setor de informática. Foi um período em que muitas
empresas nacionais sucumbiram. A Cobra buscou novos caminhos e tornou-se
integradora de soluções tecnológicas e prestadora de serviços.
No início da década de 90, a Cobra se afinou à tendência mundial de
parcerias, dentre as quais a Sun Microsystems, IBM, Cisco Systems, Microsoft,
Oracle e SCO. Por essa época, o Banco do Brasil passou a acionista
majoritário da Cobra. No final dos anos 90, entrou firme e forte no mercado
de serviços para a área bancária. Em 2009 a Cobra torna-se centro de
excelência em Software Livre.
Evolução das Marcas
1ª Marca. 2ª Marca.
3ª Marca. 4ª Marca
|
Cobra 210
|
|
|
O Cobra 210 é um
microcomputador de 8 bits, que foi projetado e desenvolvido pela Cobra
Computadores e Sistemas Brasileiros S.A.,com tecnologia totalmente
nacional. Esse equipamento era voltado para aplicações profissionais em
pequenas e médias empresas, processamento distribuído e setorial em grandes
organizações, automação de escritórios e processamento científico. O grande
acervo de programas aplicativos desenvolvido para os microcomputadores
Cobra 300 e Cobra 305 pode ser utilizado
pelo 210. Para isso, ele emprega os sistemas operacionais SOM e SPM, este
último compatível com o CP/M. As linguagens que eram disponíveis na linha
Cobra 300 (COBOL, FORTRAN, LPS e LTD), o Cobra 210 acrescentou o BASIC, de
grande divulgação entre os usuários de microcomputadores.
O projeto industrial do Cobra 210 teve por objetivo oferecer flexibilidade
na disposição física dos módulos que compõem o sistema. O equipamento é
formado por um módulo principal - incorporando processador, circuitos de
interface, fonte de alimentação, circuitos de controle e vídeo - e por um
módulo independente, contendo o teclado. O teclado é ligado ao módulo
principal por um cabo espiralado, o que permite ao usuário posicioná-lo
conforme sua conveniência.
O sistema é complementado por um ou dois módulos adicionais, cada um deles
contendo até duas unidades de discos flexíveis de 8 polegadas. O modulo de
disquetes possui as mesmas dimensões do módulo principal, só diferindo dele
quanto ao aspecto do painel frontal. Retirando-se as laterais, o módulo
principal e o dos discos podem ser acoplados, o que permite compor um
gabinete único, contendo o vídeo e de uma e quatro unidades de acionamento
de disco flexível.
O Cobra 210 apresenta o auto-teste automático, que é acionado ao se ligar a
chave. Esse teste, interno ao microcomputador, independe do sistema
operacional, tem como tarefa verificar todas as funções básicas do sistema
e diagnosticar eventuais problemas de hardware quando se liga o aparelho,
dando ao usuário a certeza de que o sistema está em perfeitas condições
operacionais.
A última linha do vídeo (linha de estado) exibe as informações geradas pelo
auto-teste, bem como a hora corrente (fornecida por um relógio interno), o
nome do programa carregado na memória e as mensagens dos sistemas
operacionais.
As dimensões do módulo são: largura = 360 mm, profundidade = 450 mm, altura
= 360 mm. O módulo principal pesa 13 kg, e o módulo de disco, contendo uma
unidade, pesa 12 kg; contendo duas unidades, 18 kg.
Unidade Central
Essa
unidade é composta de uma placa básica e de uma outra placa fixada a ela, contendo o controlador de disco flexível
para até quatro unidades.
A placa básica é composta de:
·
Microprocessador
Z 80B, operando a 5,85 MHz, com o tempo de ciclo de 171 nanossegundos e
trabalhando com um conjunto de 158 instruções, incluindo as instruções dos
microprocessadores 8080/8085.
·
RAM de 64
kbytes, utilizada para o armazenamento dos programas do usuário.
·
EPROM de
16 kbytes, utilizada para o armazenamento das rotinas de auto-teste
automático do hardware e da carga inicial do sistema operacional.
·
EEPROM
(memória permanente reprogramável) de 64 kbytes, utilizada para armazenar
os parâmetros de configuração do sistema.
·
Controlador
de vídeo, responsável pela geração dos caracteres e exibir na tela de
vídeo.
·
Interface
para teclado, para comunicação serial, padrão RS-232C assíncrono, operando
apenas no modo recepção, a uma velocidade de 4800 bps.
·
Interface
paralela para impressora, programável, constituída de 24 pinos, podendo ser
usada tanto para entrada como para saída de dados, com todo o controle de
transmissão feito por software.
·
Interface
de comunicação serial, dispondo de dois canais referentes às linhas de
comunicação 1 e 2. Admite protocolos de tipo assíncrono, síncrono a byte e
síncrono a bit. A velocidade de comunicação é programável pelo usuário,
para ambas as linhas, de forma independente, com um dos seguintes valores:
50, 75, 110, 300, 600, 1200, 2400, 4800, 9600 e 19200 bps. A linha 1 pode
ser programada com ou sem acesso direto à memória, com velocidades
distintas para transmissão e recepção. A linha 2 opera somente por
interrupção, devendo a velocidade de transmissão e a de recepção ser
iguais.
·
Interface
para cassete, usada para a ligação de um gravador cassete convencional.
Esse dispositivo auxiliar de armazenamento de dados e o software que o
manipula não são comercializados pela Cobra.
No painel traseiro do módulo principal do Cobra
210, estão os conectores para todas as interfaces, o conector para cabo de
ligação à rede elétrica, a chave ligadesliga e o controle de volume da
sinalização sonora. O Cobra 210 aceita expansão de memória, possibilitando
uma capacidade final de endereçamento de 512 kbytes.
Teclado
O teclado do Cobra 210 é do tipo máquina de
escrever, subdividido em quatro blocos:
·
Alfanumérico
padrão, com letras, números, caracteres especiais a de acentuação da língua
portuguesa.
·
Numérico
reduzido, para rápida digitação de algarismos.
·
Dois
teclados de controle e funções especiais, cuja ação depende do sistema
operacional em uso.
No total são 88 teclas, das quais 83 geram
código específico e outras quatro especificam o modo de operação: normal,
cima, alternativo e repetitivo. Cada tecla possui uma sinalização sonora,
que é acionada toda vez que a tecla pressionada é reconhecida pelo sistema.
Como característica funcional, o teclado do Cobra 210 apresenta ainda a
operação tipo 2-key rollover (mesmo que se pressione mais de uma tecla ao
mesmo tempo, somente é gerado o código da primeira tecla apertada).As dimensões do teclado são:
largura = 500 mm, profundidade = 220 mm, altura = 60 mm. O peso é de 3 kg.
Vídeo
O
vídeo do computador permite a exibição de até 27 linhas de 80 caracteres,
sendo 25 linhas para uso geral, uma para indicação de estado (exibição de
informações do sistema) e uma para separação. A tela é de fósforo verde,
com 31 cm na diagonal, dotada de características antirefletoras. Cada
caractere formado no vídeo é representado dentro de uma matriz de 7 x 9,
contido numa matriz de 9 x 11 pontos, possibilitando alta resolução.
Os caracteres podem ser programados para
exibição intensificada, piscante, sublinhada, apagada (não-exibidos) e em
vídeo reverso (caracteres escuros contra fundo claro).
O cursor pode ser do tipo traço piscante, traço não-piscante, bloco em
vídeo reverso piscante e bloco em vídeo reverso não-piscante.
O vídeo do microcomputador Cobra 210 pode exibir dois conjuntos de
caracteres: USASC II estendido, incluindo caracteres acentuados da língua portuguesa,
e semigráficos, para elaboração de tabelas, histogramas, formulários, etc.
Memória Auxiliar
O
sistema Cobra 210 permite o acondicionamento de até dois módulos de discos
flexíveis de 8 polegadas, cada um contendo até duas unidades de disco. Caso
seja usada apenas uma unidade de um módulo, a abertura à sua esquerda é
fechada por um painel cego.
Cada módulo de disco é alimentado e controlado totalmente pelo módulo
principal do microcomputador, não havendo qualquer controle acessível ao
usuário.
Os módulos de disco possuem as seguintes características:
- Utilizam
dois discos flexíveis de 8 polegadas, formatados por software com 77
trilhas, cada trilha com 15, 16, 26 ou 30 setores, e 128, 256 ou 512
bytes por setor, conforme o sistema operacional em uso e a formatação
selecionada pelo usuário.
·
Os discos podem ser de densidade
simples ou dupla e face simples ou dupla, com a capacidade total de
armazenamento de 1,2 Mbytes (formatado).
Disco rígido
Winchester, acomodado nos módulos de discos flexíveis. No total, o sistema
aceita de 5 a 10 Mbytes de armazenamento em disco rígido de tecnologia
Winchester.
Gravador cassete convencional, utilizado apenas como dispositivo auxiliar
de armazenamento de dados, já que os sistemas operacionais e os programas
utilitários são baseados em discos. Essa restrição, entretanto, em nada
impede a utilização do cassete, desde que o usuário desenvolva as rotinas
de geração a detecção de dados.
Está prevista, todavia,
para futuras versões do microcomputador, a inclusão de facilidades de
manipulação de cassete através das linguagens BASIC e LPS.
Software Aplicativo
O
Cobra 210 dispõe de dois sistemas operacionais, cada um atendendo a uma
determinada área de aplicação e suportando diferentes pacotes de software:
o SOM - Sistema Operacional Monoprogramável - e o SPM - Sistema Padrão para
Microcomputadores (compatível com o CP/M).
O sistema operacional SOM é voltado para aplicações comerciais,
administrativas e científicas. Permite a utilização do Cobra 210 como
terminal inteligente de outro computador de maior porte (por exemplo, o
Cobra 530), e como estação interativa de entrada remota para máquinas IBM.
O SOM possibilita facilidades para manipulação de arquivos, execução de
programas, listagem do diretório do disco e manutenção do disco.
O sistema operacional SPM tem como característica básica a total
compatibilidade com o sistema CP/M versão 2.2.
A
Características básicas
Fabricante: Cobra
UCP:
Zilog Z80B, com 5,85 Mhz
Video:Monitorintegrado
ao gabinete com tela de 12", texto: 26 lin x 80 cols (uma linha
reservada para informação do sistema)
Teclado: 88
teclas, numérico reduzido e teclas de funções especiais e de especificação
do modo de operação, caracteres ASCII e símbolos específicos da Língua
Portuguesa.
Rom: 16
Kb
Ram:
64 Kb com expansão até 512 Kb
Memória externa:
até 04 Discos flexíveis de 8" face e densidade dupla de 1,2 mb ,
winchester de 10 Mb, gravador cassete.
Entradas/Saídas:
Interface paralela, duas saídas RS 232, três slots livres para expansão e
via rápida (comunicação com cabo coaxial)
Sistema
operacional: BASIC, SOM, MUMPS e SPM compatível com
CP/M
Comentário: O
Cobra 210 foi o primeiro da linha Cobra a usar BASIC.
|
|
|
Unix
|
Unix
|
|
|
|
|
|
|
|
Código fechado,
agora alguns projectos Unix (BSD família e Open Solaris) são de código
aberto.
|
|
Lançado em:
|
|
|
|
|
|
|
História
Linha do tempo
dos variantes do Unix.
O Multics deveria ser um sistema de tempo compartilhado para uma grande
comunidade de usuários. Entretanto, os recursos computacionais disponíveis à
época, particularmente os do computador utilizado, um GE 645, revelaram-se insuficientes para as pretensões do
projeto. Em 1969, a
Bell retirou-se do projeto. Duas razões principais foram citadas para explicar
a sua saída. Primeira: três instituições com objetivos díspares dificilmente
alcançariam uma solução satisfatória para cada uma delas (o MIT fazia pesquisa,
AT&T monopolizava os serviços de telefonia americanos e a GE queria vender
computadores). A segunda razão é que os participantes sofriam da síndrome do
segundo projeto e, por isso, queriam incluir no Multics tudo que tinha sido
excluído dos sistemas experimentais até então desenvolvidos.
Ainda em 1969, Ken
Thompson, usando um ocioso computador PDP-7,
começou a reescrever o Multics num conceito menos ambicioso, batizado de Unics,
usando linguagem de montagem (assembly). Mais tarde, Brian Kernighan rebatizou o novo sistema de Unix.
Um marco importante foi estabelecido em 1973, quando Dennis Ritchie e Ken
Thompson reescreveram o Unix, usando a linguagem C, para um computador PDP-11. A linguagem C havia sido desenvolvida por Ritchie para
substituir e superar as limitações da linguagem B, desenvolvida por Thompson. O seu uso é considerado uma das principais
razões para a rápida difusão do Unix.
Em 1977, a AT&T começou a fornecer o Unix para instituições comerciais.
A abertura do mercado comercial para o Unix deve muito a Peter Weiner -
cientista de Yale e fundador da Interactive System Corporation. Weiner
conseguiu da AT&T, então já desnudada de seu monopólio nas comunicações e
liberada para atuação no mercado de software, licença para transportar e
comercializar o Unix para o computador Interdata 8/32 para ambiente de
automação de escritório. O Unix saía da linha das máquinas PDP, da Digital
Equipament Corporation (DEC), demonstrando a relativa facilidade de migração
(transporte) para outros computadores, e que, em parte, deveu-se ao uso da
linguagem C. O sucesso da Interactive de Weiner com seu produto provou que o
Unix era vendável e encorajou outros fabricantes a seguirem o mesmo curso.
Iniciava-se a abertura do chamado mercado Unix.
Com a crescente oferta de microcomputadores, outras empresas transportaram
o Unix para novas máquinas. Devido à disponibilidade dos fontes do Unix e à sua
simplicidade, muitos fabricantes alteraram o sistema, gerando variantes
personalizadas a partir do Unix básico licenciado pela AT&T. De 1977 a
1981, a AT&T integrou muitas variantes no primeiro sistema Unix comercial
chamado de System III. Em 1983, após acrescentar vários melhoramentos ao System
III, a AT&T apresentava o novo Unix comercial, agora chamado de System V.
Hoje, o Unix System V é o padrão internacional de fato no mercado Unix,
constando das licitações de compra de equipamentos de grandes clientes na
América, Europa e Ásia.
Atualmente, Unix (ou *nix) é o nome dado a uma grande família de Sistemas Operativos que partilham muitos dos conceitos dos Sistemas Unix
originais, sendo todos eles desenvolvidos em torno de padrões como o POSIX
(Portable Operating System Interface) e outros. Alguns dos Sistemas Operativos derivados do Unix são: BSD (FreeBSD, OpenBSD e NetBSD), Solaris (anteriormente conhecido por SunOS), IRIXG, AIX, HP-UX, Tru64, SCO, Linux (nas suas centenas de distribuições), e até o Mac OS X
(baseado em um núcleo Mach BSD chamado Darwin). Existem mais de quarenta sistemas operacionais *nix,
rodando desde celulares a supercomputadores, de relógios de pulso a sistemas de
grande porte.
Características
Sistema
operacional multitarefa
Multitarefa significa executar uma ou mais tarefas ou processos simultaneamente. Na
verdade, em um sistema monoprocessado, os processos são executados
seqüencialmente de forma tão rápida que parecem estar sendo executados
simultaneamente. O Unix escalona sua execução e reserva-lhes recursos
computacionais (intervalo de tempo de processamento, espaço em memória RAM,
espaço no disco rígido, etc.).
O Unix é um sistema operacional de multitarefa preemptiva. Isso significa
que, quando esgota-se um determinado intervalo de tempo (chamado quantum),
o Unix suspende a execução do processo, salva o seu contexto (informações
necessárias para a execução do processo), para que ele possa ser retomado posteriormente,
e coloca em execução o próximo processo da fila de espera. O Unix também
determina quando cada processo será executado, a duração de sua execução e a
sua prioridade sobre os outros.
A multitarefa, além de fazer com que o conjunto de tarefas seja executado
mais rapidamente, ainda permite que o usuário e o computador fiquem livres para
realizarem outras tarefas com o tempo economizado.
Sistema
operacional multiutilizador
Uma característica importante do Unix é ser multiusuário (multiutilizador). Bovet e Cesati [4] definem um sistema multiusuário como
"aquele capaz de executar, concorrente e independentemente, várias
aplicações pertencentes a dois ou mais usuários". O Unix possibilita que
vários usuários usem um mesmo computador simultaneamente, geralmente por meio
de terminais. Cada terminal é composto de um monitor, um teclado e,
eventualmente, um mouse. Vários terminais podem ser conectados ao mesmo
computador num sistema Unix. Há alguns anos eram usadas conexões seriais, mas
atualmente é mais comum o uso de redes locais, principalmente para o uso de
terminais gráficos (ou terminais X), usando o protocolo XDMCP.
O Unix gerencia os pedidos que os usuários fazem, evitando que um interfira
com outros. Cada usuário possui direitos de propriedade e permissões sobre
arquivos. Quaisquer arquivos modificados pelo usuário conservarão esses
direitos. Programas executados por um usuário comum estarão limitados em termos
de quais arquivos poderão acessar.
O sistema Unix possui dois tipos de usuários: o usuário root (também
conhecido como superusuário), que possui a missão de administrar o sistema,
podendo manipular todos os recursos do sistema operacional; e os usuários
comuns, que possuem direitos limitados.
Para que o sistema opere adequadamente em modo multiusuário, existem alguns
mecanismos: (i) um sistema de autenticação para identificação de cada usuário
(o programa login, p.ex.,
autentica o usuário verificando uma base de dados, normalmente armazenada no
arquivo /etc/passwd);
(ii) sistema de arquivos com permissões e propriedades sobre arquivos (os
direitos anteriormente citados); (iii) proteção de memória, impedindo que um
processo de usuário acesse dados ou interfira com outro processo. Esse último
mecanismo é implementado com a ajuda do hardware, que consiste na divisão do
ambiente de processamento e memória em modo supervisor (ou modo núcleo) e modo
usuário.
Arquivos de dispositivo
Uma característica singular no Unix (e seus derivados) é a utilização
intensiva do conceito de arquivo. Quase todos os dispositivos são tratados como
arquivos e, como tais, seu acesso é obtido mediante a utilização das chamadas
de sistema open, read, write
e close.
Os dispositivos de entrada e saída são classificados como sendo de bloco
(disco, p.ex.) ou de caractere (impressora, modem, etc.) e são associados a
arquivos mantidos no diretório /dev
(v. detalhamento mais adiante).
Estrutura
A estrutura do
sistema Unix.
Um sistema Unix
consiste, basicamente, de duas partes:
- Núcleo - o núcleo do sistema
operacional, a parte que relaciona-se diretamente com o hardware, e que
executa num espaço de memória privilegiado. Agenda processos, gerencia a
memória, controla o acesso a arquivos e a dispositivos de hardware (estes,
por meio dos controladores de dispositivo - drivers - e
interrupções). O acesso ao núcleo é feito por chamadas de sistema, que são
funções fornecidas pelo núcleo; essas funções são disponibilizadas para as
aplicações por bibliotecas de sistema C (libc).
- Programas
de sistema - são aplicações, que executam em espaços de
memória não privilegiados, e que fazem a interface entre o usuário e o
núcleo. Consistem, principalmente, de:
·
Conjunto de bibliotecas C (libc)
·
Shell - um ambiente que permite que o usuário digite comandos.
·
Programas utilitários diversos - são programas
usados para manipular arquivos, controlar processos, etc.
·
Ambiente gráfico (GUI) graphics
user interface - eventualmente utiliza-se também um ambiente gráfico para
facilitar a interação do usuário com o sistema.
Em um sistema Unix, o espaço de memória utilizado pelo núcleo é denominado
espaço do núcleo ou supervisor (em inglês: kernel
space); a área de memória
para os outros programas é denominada espaço do usuário (user space).
Essa separação é um mecanismo de proteção que impede que programas comuns
interfiram com o sistema operacional.
Processos
Um processo, na visão mais simples, é uma instância de um programa em
execução. Um programa, para ser executado, deve ser carregado em memória; a
área de memória utilizada é dividida em três partes: código (text),
dados inicializados (data) e pilha (stack).
Por ser um sistema multitarefa, o Unix utiliza uma estrutura chamada tabela
de processos, que contém informações sobre cada processo, tais como:
identificação do processo (PID), dono, área de memória utilizada, estado (status).
Apenas um processo pode ocupar o processador em cada instante - o processo
encontra-se no estado "executando" (running). Os outros
processos podem estar "prontos" (ready), aguardando na fila de
processos, ou então estão "dormindo" (asleep), esperando
alguma condição que permita sua execução.
Um processo em execução pode ser retirado do processador por duas razões:
(i) necessita acessar algum recurso, fazendo uma chamada de sistema - neste
caso, após sua retirada do processador, seu estado será alterado para
"dormindo", até que o recurso seja liberado pelo núcleo; (ii) o
núcleo pode interromper o processo (preempção) - neste caso, o processo irá
para a fila de processos (estado "pronto"), aguardando nova
oportunidade para executar - ou porque a fatia de tempo esgotou-se, ou porque o
núcleo necessita realizar alguma tarefa.
Existem quatro chamadas de sistema principais associadas a processos: fork, exec,
exit e wait. fork
é usada para criar um novo processo, que irá executar o mesmo código (programa)
do programa chamador (processo-pai); exec
irá determinar o código a ser executado pelo processo chamado (processo-filho);
exit termina o
processo; wait faz a
sincronização entre a finalização do processo-filho e o processo-pai.
Sistema
de arquivos
Sistema de arquivos é uma estrutura lógica que possibilita o armazenamento
e recuperação de arquivos. No Unix, arquivos são contidos em diretórios (ou
pastas), os quais são conectados em uma árvore que começa no diretório raiz
(designado por /). Mesmo os arquivos que se encontram em dispositivos de
armazenamento diferentes (discos rígidos, disquetes, CDs, DVDs, sistemas de
arquivos em rede) precisam ser conectados à árvore para que seu conteúdo possa
ser acessado. Cada dispositivo de armazenamento possui a sua própria árvore de
diretórios.
O processo de conectar a árvore de diretórios de um dispositivo de
armazenamento à árvore de diretórios raiz é chamado de "montar dispositivo
de armazenamento" (montagem) e é realizada por meio do comando mount. A montagem associa o
dispositivo a um subdiretório.
Estrutura de
diretórios
A árvore de
diretórios do Unix é dividida em várias ramificações menores e pode variar de
uma versão para outra. Os diretórios mais comuns são os seguintes:
/ — Diretório raiz - este é o diretório principal do
sistema. Dentro dele estão todos os diretórios do sistema.
/bin — Contém arquivos, programas do sistema, que são usados
com freqüência pelos usuários.
/boot — Contém arquivos necessários para a inicialização do
sistema.
/dev — Contém arquivos usados para acessar dispositivos
(periféricos) existentes no computador.
/etc — Arquivos de configuração de seu computador local.
/home — Diretórios contendo os arquivos dos usuários.
/lib — Bibliotecas compartilhadas pelos programas do sistema
e módulos do núcleo.
/mnt — Diretório de montagem de dispositivos.
/mnt/cdrom — Subdiretório onde são montados os CDs. Após a
montagem, o conteúdo do CD se encontrará dentro deste diretório.
/mnt/floppy — Subdiretório onde são montados os disquetes. Após a
montagem, o conteúdo do disquete se encontrará dentro deste diretório.
/proc — Sistema de arquivos do núcleo. Este diretório não
existe, ele é colocado lá pelo núcleo e usado por diversos programas.
/root — Diretório do usuário root.
/sbin — Diretório de programas usados pelo superusuário (root)
para administração e controle do funcionamento do sistema.
/tmp — Diretório para armazenamento de arquivos temporários
criados por programas.
/usr — Contém maior parte de seus programas. Normalmente
acessível somente como leitura.
/var — Contém maior parte dos arquivos que são gravados com
freqüência pelos programas do sistema.
Particularidades
Um sistema Unix é orientado a arquivos, quase
tudo nele é arquivo. Seus comandos são na verdade arquivos executáveis, que são encontrados em lugares previsíveis em sua árvore de diretórios, e até mesmo a comunicação entre entidades e processos é feita por estruturas parecidas com arquivos.
O acesso a arquivos é organizado através de propriedades e proteções. Toda a segurança do
sistema depende, em grande parte, da combinação entre as propriedades e
proteções definidas em seus arquivos e suas contas de usuários.
Aplicações
O Unix permite a execução de pacotes de softwares aplicativos para apoio às
diversas atividades empresariais. Dentre estes pacotes destacam-se:
- geradores
gráficos
- planilhas
eletrônicas
- processadores
de textos
- geradores
de aplicações
- linguagens
de 4° geração
- banco
de dados
O Unix possui recursos de apoio à comunicação de dados, que proporcionam
sua integração com outros sistemas Unix, e até com outros sistemas operacionais
distintos. A integração com sistemas heterogêneos permite as seguintes
facilidades:
- compartilhamento
de recursos e informações
- transferência
de informações
- comunicação
entre usuários remotos
- submissão
de programas para serem executados em computadores remotos
- utilização
dos terminais de uma máquina Unix como terminais de outras máquinas
remotas, mesmo com sistemas operacionais distintos.
Para última, o Unix oferece um ambiente integrado e amigável, voltado para
a gestão automatizada de escritório, com serviços que atenderão às seguintes
áreas:
- arquivamento
eletrônico de informações
- processador
de documentos
- agenda
e calendário
- calculadora
- correio
eletrônico
X Window
System
Além do shell, o Unix suporta interface
gráfica para o usuário. Nas
primeiras versões do Unix as interfaces do usuário eram baseadas apenas em
caracteres (modo texto) e o sistema compunha-se apenas do núcleo, de
bibliotecas de sistema, do shell e de alguns outros aplicativos. As
versões mais recentes do Unix, além de manterem o shell e seus comandos,
incluem o X Window System que, graças ao gerenciador de exibição e ao gerenciador de
janelas, possui uma interface
atraente e intuitiva que aumenta em muito a produtividade do usuário.
Desenvolvido no MIT (Massachussets
Institute of Technology), o X Window System (também pode ser chamado de
Xwindow) tornou-se o sistema gráfico do Unix. O Xwindow funciona como gerenciador
de exibição e por si só, não faz muita coisa. Para termos um ambiente gráfico
produtivo e completo, precisamos também de um gerenciador de janelas.
O gerenciador de janelas proporciona ao ambiente gráfico a aparência e as
funcionalidades esperadas incluindo as bordas das janelas, botões, truques de mouse,
menus etc. Como no sistema Unix o gerenciador de exibição (X Window System) é
separado do gerenciador de janelas, dizemos que seu ambiente gráfico é do tipo cliente-servidor. O Xwindow funciona como servidor e interage diretamente
com o mouse, o teclado e o vídeo. O gerenciador de janelas funciona como
cliente e se aproveita dos recursos disponibilizados pelo Xwindow.
O fato de o Unix possuir o gerenciador de exibição (Xwindow) separado do
gerenciador de janelas tornou possível o surgimento de dezenas de gerenciadores
de janelas diferentes. Os gerenciadores de janelas mais comuns no mundo Unix
são o Motif, Open
Look, e o CDE.
Também existem outros gerenciadores de janelas que são bastante utilizados no
Unix, principalmente nos sistemas Unix-Like (versões gratuitas e clones do
Unix). São eles: KDE, Gnome, FVWM, BlackBox, Enlightenment, WindowMaker etc.
Comandos
Esta é uma lista de programas
de computador para o sistema operacional Unix e os sistemas compatíveis, como o Linux. Os
comandos do Unix tornam-se acessíveis ao usuário a partir do momento em que ele
realiza o login no sistema. Se o usuário utiliza tais comandos, então ele se
encontra no modo shell, também chamado de modo texto (ou Unix tradicional).
Quando estiver utilizando o modo gráfico, o usuário também poderá se utilizar
de tais comandos desde que abra uma janela de terminal (Xterm).
A linha de comando do sistema operacional Unix permite a realização de
inúmeras tarefas através de seus comandos, de manipulação de arquivos a
verificação do tráfego em rede. Para exibir uma descrição detalhada de cada
comando abra uma console ou xterm e digite man comando, onde
comando é o comando em questão.
.
Sistema operacional tipo Unix
Diagrama da relação de vários sistemas Unix-like
Um sistema operacional do tipo Unix (Unix-like em inglês)
referido também como UN*X ou *nix é um sistema similar ao Unix, não
estando necessariamente de acordo com o Single
UNIX Specification.
Definição
The Open Group possui a marca registrada do UNIX e administra a Single UNIX Specification, sendo o nome
"UNIX" uma certificação de produto. O Open Group não aprova a
utilização do verbete "Unix-like", e considera uma utilização
incorreta de sua marca patenteada, visto que "UNIX" em suas melhores
práticas precisa ser escrito em caixa alta distinguindo-se do texto ao seu
redor, e não para denotar um termo genérico para "sistema" através de
palavras que contém hífem.[1]
Outros tratam o termo "Unix" como uma marca genérica, adicionando o curinga asterisco, gerando as abreviações Un*x ou *nix,[2] visto
que Sistemas do tipo Unix possuem nomes como AIX, HP-UX, IRIX, Linux, Minix, Ultrix e Xenix. Estes padrões podem não fechar de forma literal com o
nome dos sistemas, mas estes sistemas são reconhecidos como descendentes Unix
ou Sistemas Operacionais do tipo Unix, mesmo aqueles com nomes não-similares
como o Solaris ou o FreeBSD.
Tru64 UNIX
|
Tru64
UNIX
|
|
|
|
|
|
Código-fonte fechado
|
|
|
5.1B-4
|
|
Família do SO:
|
|
|
|
|
|
|
|
|
|
Atual
|
|
|
|
|
|
Como seu nome original sugere, o Tru64 UNIX é baseado no sistema
operacional OSF/1. O produto UNIX anterior da DEC era conhecido como Ultrix e era baseado no BSD
UNIX.
Diferente da maioria das implementações UNIX comerciais, o Tru64 UNIX é
construído sobre o núcleo Mach.
Outras implementações UNIX que o utilizam incluem NeXTSTEP, MkLinux e Mac OS X.
Digital UNIX
Em 1995, a partir da versão 3.2, a DEC renomeou o sistema DEC OSF/1 AXP
para Digital UNIX, para refletir sua conformidade com a Single
UNIX Specification do consórcio X/Open
Tru64 UNIX
Após a compra da DEC pela Compaq em 1998, com o
lançamento da versão 4.0F, o Digital UNIX foi renomeado para Tru64 UNIX para
enfatizar sua natureza 64-bit e remover a referência à marca Digital.
Estado
atual
Com a compra da Compaq pela HP em 2002 a HP
anunciou planos para migrar alguns dos recursos mais inovadores do Tru64 UNIX
para o HP-UX, sua
versão própria do Unix. Em dezembro de 2004 no entanto, a HP aparentemente
cancelou o projeto, abandonando a implementação desses recursos. No processo,
muitos dos desenvolvedores Tru64 restantes foram demitidos.
Em 2007, a HP mantém o compromisso de oferecer suporte ao Tru64 UNIX até ao
menos 2012. Com a próxima versão de manutenção do sistema planejado para 2008
(5.1B-5).
O Kernel
O Kernel do Unix (e de virtualmente qualquer
outro sistema operacional) possui um papel de que convém ter noções, a fim de
se poder compreender melhor o funcionamento do sistema, realizar diagnósticos e
procedimentos administrativos como adição de componentes de hardware. Algum
conhecimento do papel do kernel é importante também para se ter uma noção mais
clara do uso de arquivos especiais e do diretório /proc.
O Kernel ordinariamente reside no filesystem como
um outro arquivo qualquer. No Linux, ele é em geral o arquivo /vmlinuz
ou /boot/vmlinuz, ou ainda /boot/vmlinuz-2.0.36. Ele é um
programa, ainda que um pouco diferente dos programas de aplicação como o /bin/ls.
O kernel é carregado e posto em execução no boot da máquina, e a sua execução
somente se encerra com o shutdown.
De forma simplificada, o seu papel é num primeiro
momento reconhecer o hardware e inicializar os respectivos drivers. Em seguida
ele entra num estado administrativo onde funciona como intermediário entre as
aplicações e o hardware. Por exemplo, quando uma aplicação necessita alocar
mais memória, ela solicita isso ao kernel. É o kernel que distribui o tempo de
CPU aos vários processos ativos. É ele que habitualmente realiza a entrada e
saída de dados nas diferentes portas de comunicação.
É por isso que a adição de hardware novo a uma
máquina pode requerer a substituição ou ao menos a reconfiguração do kernel. Os
kernels mais recentes do Linux oferecem vários mecanismos de configuração que
os tornam sobremaneira flexíveis, a ponto de ser rara a necessidade de
substituição do kernel. Os dois mecanismos fundamentais de se configurar a
operação do kernel são a passagem de parâmetros no momento do boot (realizada
pelo LILO) e a carga de módulos, feita manualmente ou por mecanismos
automáticos como o kerneld.
O diálogo entre as aplicações e o kernel realiza-se
fundamentalmente através dos system calls, que são serviços que o kernel
oferece, como por exemplo read(2). Os device special files são maneiras
de se referir ao kernel os dispositivos físicos ou lógicos com que se pretende
operar, por exemplo a primeira porta serial ou a segunda unidade de fita, ou o
disco principal do sistema. Neles, o importante não é o nome, mas sim os
números de dispositivo, ou mais precisamente o major e o minor device numbers.
Device special files são criados através do comando mknod, ou através de
interfaces mais amigáveis, como o comando MAKEDEV.
Os sistemas Unix-like mais recentes oferecem um
outro mecanismo de comunicação com o kernel, que é o filesystem /proc.
As entradas desse filesystem são pseudo-arquivos cujo conteúdo reflete o estado
atual de inúmeras estruturas de dados internas do kernel. Assim, um programa de
aplicação passa a poder comunicar-se com o kernel através dos mecanismos
ordinários de leitura e escrita de arquivos.
Em muitos casos a comunicação entre as aplicações e
o kernel é intermediada por bibliotecas, principalmente a libc. Elas
oferecem serviços de mais alto nível que os system calls do kernel, tornando
mais simples o trabalho de programação.
- Executar a conexão ao
sistema remoto como indicada acima.
- Iniciar
o ppp no sistema remoto.
- Disparar
o pppd localmente.
Em PCs, os conectores externos das portas seriais são conectores DB-9
ou DB-25 macho, e os das paralelas são DB-25 fêmea.
Unix é um sistema operacional criado por Kenneth Thompson após um
projeto de sistema operacional não ter dado certo. O Unix foi o primeiro
sistema a introduzir conceitos muito importantes para SOs como suporte a
multiusuários, multitarefas e portabilidade.
Além disso, o Unix suporta tanto alterações por linhas de comando,
que dão mais flexibilidade e precisão ao usuário, quanto definições via
interface gráfica, uma opção normalmente mais prática e menos trabalhosa do que
a anterior.
Sua história remonta aos anos de 1960, quando Thompson, Dennis
Ritchie e outros desenvolvedores se juntaram para desenvolver o sistema
operacional Multics nos Laboratórios Bell da AT&T. A ideia era criar um
sistema capaz de comportar centenas de usuários, mas diferenças entre os grandes
grupos envolvidos na pesquisa (AT&T, General Eletronic e Instituto de
Tecnologia de Massachusetts) levaram o Multics ao fracasso. Contudo, em 1969,
Thompson começou a reescrever o sistema com pretensões não tão grandes, e aí
surge o Unics.
O passo seguinte foi um retoque no nome e ele passa a se chamar
Unix. Em 1973, com ajuda de Dennis Ritchie, a linguagem empregada no sistema
passa a ser a C, algo apontado como um dos principais fatores de sucesso do
sistema. Atualmente, uma série de SOs são baseados no Unix, entre eles, nomes
consagrados como Gnu/Linux, Mac OS X, Solaris e BSD.
Apesar de não haver uma resposta exata para isso, a esmagadora
maioria dos sistemas disponíveis atualmente é baseada no Unix. Talvez você nem
saiba, mas o sistema operacional que roda no caixa eletrônico onde você saca
dinheiro, por exemplo, provavelmente é um do tipo Unix.
Multitarefa e multiusuário
É provável que o primeiro grande motivo da popularidade deste
sistema sejam os conceitos que ele lançou no mundo
dos SOs. Ao contrário de seus principais
“concorrentes”, o Unix propôs um sistema multitarefa, capaz de executar dezenas
de processos simultaneamente. De fato, a execução no Unix se dava de forma
extremamente rápida, o que o fazia parecer ser multitarefa.
Outra característica do Unix é o suporte a multiusuário. O sistema
permite que várias aplicações sejam executadas de modos independente e
concorrente por usuários diferentes. Assim, eles podem compartilhar não somente
hardwares, mas também softwares e componentes como discos rígidos e
impressoras.
Atualmente, esses recursos parecem óbvios, mas há 40 anos eram
novidades e fortes diferenciais para a escolha de um sistema operacional. Vale
lembrar ainda que, nessa época, computadores pessoais também pareciam um sonho
distante e o Unix era usado, basicamente, por universidades, governos e grandes
indústrias.
Distribuição livre
Outro fator que com certeza influenciou na popularidade do Unix
foi ele ter funcionado sob uma licença livre em seus primeiros anos de vida,
tendo sido distribuído gratuitamente para universidades e órgãos governamentais
dos Estados Unidos. Apenas depois de algum tempo a licença se tornou
proprietária.
Contudo, a maioria dos sistemas criados com base no Unix funciona
sob um sistema total ou parcial de código aberto. Desse modo, a proliferação do
sistema foi impulsionada pela licença livre, principalmente das famílias BSD,
Open Solaris e Linux.
AmpliarAmbiente gráfico X rodando no Unix no
final dos anos 80. (Fonte da imagem: Liberal Classic)
Por que a Microsoft não usa o Unix?
Essa história começa a ser contada no ano de 1979, quando a IBM necessitava de
um sistema operacional para um novo computador e contratou a Microsoft para
realizar o serviço. Como a empresa de Bill Gates não possuía um sistema
próprio, ela adquiriu o Q-DOS, modificou-o e deu um novo nome a ele: MS-DOS.
MS-DOS, também conhecido apenas por DOS, é um acrônimo para
“sistema operacional de disco da Microsoft” e foi a base dos sistemas Windows
até o lançamento do Windows 2000. O DOS coordenava o funcionamento do
computador, fazendo uma “ponte” entre o hardware e os aplicativos.
Então, a resposta à pergunta desta seção pode ser: por falta de
interesse. Além das diferenças básicas entre o Q-DOS/MS-DOS (que tinha como
características ser monotarefa e monousuário) e o Unix, o DOS foi a escolha de
Bill Gates para entrar no mercado de PCs. Ele preferiu agregar um produto
“menor” à sua empresa para vendê-lo à IBM.
Sistemas Unix e tipo Unix
É importante fazer uma ressalva. Unix é um sistema proprietário,
justamente por isso softwares como distribuições de Linux e o Mac OS são
chamadas de “tipo Unix”. Para um sistema ser considerado Unix, é preciso se
enquadrar completamente no “Single Unix Specifications” ou Especificações
Únicas do Unix, em tradução livre.
Essas especificações foram definidas pela norma Posix, criada a
partir de um projeto desenvolvido em 1985 para padronizar os sistemas variantes
do Unix. Se tomarmos Windows, Mac e Linux, os principais sistemas operacionais
da atualidade, apenas o SO da Microsoft não faz uso de uma arquitetura baseada
no Unix.
Mais seguro?
Essa é uma questão um tanto quanto polêmica. Muitos falam que o
Windows é vulnerável demais, enquanto outros dizem que sistemas Linux e Mac
(baseados no Unix) não são infectados por vírus. A controvérsia é tanta que até
já fez parte da seção “Mito
ou Verdade” aqui no Tecmundo.
O que se pode dizer é que, normalmente, sistemas baseados no Unix
têm uma estrutura de execução de processos e de instalação de aplicativos um
pouco mais complicada do que o Windows. Acaba sendo mais simples instalar um
aplicativo executável no Windows do que compilar um pacote TAR.GZ no Linux, por
exemplo.
Isso, somado à esmagadora popularidade do Windows entre os
usuários, acaba por torná-lo um sistema mais vulnerável do que seus
concorrentes. Contudo, o diretor executivo da Symantec, criadora do Norton
Antivirus, Enrique Salem, afirmou
em fevereiro deste ano que Mac OS não é mais
seguro do que Windows.
Vários movimentos no sentido de descomplicar o uso das dezenas de
distribuições de Linux têm tornado o uso do sistema cada vez mais convencional,
o que pode acarretar em problemas semelhantes aos do Windows. De qualquer modo,
a estrutura dos sistemas tipo Unix talvez torne mais difícil a infecção por
malwares.
Essa foi a história de um dos mais importantes componentes de
software da história da informática. Não deixe de registrar a sua opinião nos
comentários.
Minix
|
|
|
|
|
|
|
|
|
|
3.2.0 / ?
|
|
Família do SO:
|
|
|
|
|
|
|
|
|
|
Corrente
|
|
|
|
|
|
Características
·
Multitarefa
(múltiplos programas podem correr ao mesmo tempo ).
·
Suporta memória estendida (16MB no 286 e 4GB no 386, 486
e Pentium ou superior).
·
RS-232 serial line suporte com terminal emulation,
kermit, zmodem, etc.
·
Máximo de três usuários simultaneamente na mesma máquina.
·
Chamadas de sistemas compatíveis com POSIX.
·
Inteiramente escrito em C (SO, utilitários, bibliotecas
etc.).
·
Compilador ANSI C.
·
Shell funcionalmente idêntico ao Bourne shell.
·
Rede TCP/IP.
·
5 editores (emacs subset, vi clone, ex, ed, and simple
screen editor).
·
Mais de 200 utilitários (cat, cp, ed, grep, kermit, ls,
make, sort, etc.).
·
Mais de 300 bibliotecas (atoi, fork, malloc, read, stdio,
etc.).
·
O sistema roda apenas em modo texto.
Foi organizado em camadas, onde as duas primeiras formam
o núcleo:
- Captura
interrupções e traps, salvar e restaurar registradores, agendar as demais
funções
- Processos
de entrada/saída.
- As
tarefas de entrada/saída são
chamadas drivers de dispositivos;
- Contém
processos que fornecem serviços úteis ao usuário;
- Existem
em um nível menos privilegiado que o núcleo;
- Shell,
editores, compiladores, etc.
História
Quando o Unix era jovem (Versão 6), o código-fonte estava amplamente
disponível, sob licença da AT&T, e era muito estudado. John Lions, da
Universidade New South Wales, na Austrália, escreveu uma pequena brochura que
descrevia sua operação, linha por linha(Lions,1996). Essa publicação era
utilizada(com permissão de AT&T)como referência em muitos cursos
universitários sobre sistemas operacionais. Quando a AT&T lançou a Versão
7, começou-se a perceber que o UNIX era um produto comercial valioso, e assim
ela lançou essa versão com uma licença proibindo que o código-fonte fosse
estudado em cursos, para evitar pôr em risco seu status de segredo de negócio.
Muitas Universidades tiveram de conformar-se em simplesmente acabar com o
estudo de UNIX e ensinar só teoria. Infelizmente, ensinar só teoria deixa o
aluno com uma visão equivocada do que é realmente um sistema operacional. Os
temas teóricos que normalmente são abordados detalhadamente em cursos e em
livros sobre sistemas operacionais, como algoritmos de agendamento, não são
realmente tão importantes na prática. Os assuntos realmente relevantes, como
E/S e sistemas de arquivos, geralmente são negligenciados, pois há pouca teoria
sobre eles. Para corrigir essa situação, Tanenbaum decidiu escrever um novo
sistema operacional a partir do zero, que seria compatível com UNIX do ponto de
vista do usuário, mas completamente diferente interiormente. Por não usar
sequer uma linha do código da AT&T, esse sistema evita restrições de
licenciamento, assim ele pode ser utilizado para estudo individual ou em
classe. Desta maneira, os leitores podem dissecar um sistema operacional real
para ver o que há por dentro. O nome MINIX significa mini-UNIX pois ele é tão
pequeno que mesmo um não especialista pode entender seu funcionamento. Além da
vantagem de eliminar os problemas legais, o MINIX tem outra vantagem sobre o
UNIX. Foi escrito uma década depois do UNIX e estruturado de maneira modular. O
sistema de arquivos do MINIX, por exemplo, não é absolutamente parte do sistema
operacional, mas roda como um programa de usuário. Outra diferença: enquanto p
UNIX foi projetado para ser eficiente, o MINIX foi para ser legível(se é que
alguém pode falar que um programa com centenas de páginas como sendo legível).
O código do MINIX, por exemplo, tem
milhares de comentários. O MINIX originalmente foi projetado para ter
compatibilidade com a Versão 7(V7) do UNIX, a qual era utilizada como modelo
por causa de sua simplicidade e elegância. Às vezes, diz-se que a Versão 7 não
era só uma melhora em relação a todos os seus sucessores, como também sobre
todos os seus sucessores. Com o advento do POXIX, o MINIX começou a
desenvolver-se em direção ao novo padrão, mas ainda mantendo
retrocompatibilidade com programas existentes. Essa espécie de evolução é comum
na indústria dos computadores, na medida em que nenhum fabricante iria querer
lançar um sistema que nenhum dos seus clientes pudesse utilizar sem passar por
grandes adaptações.
Como o UNIX, o MINIX foi escrito na linguagem de programação C e projetado
para ser facilmente portado para vários computadores. A implementação inicial
era para o IBM PC, pois esse computador era mais amplamente utilizado.
Posteriormente, ele foi portado para computadores Atari, Amiga, Macintosh e
SPARC. Para manter-se fiel à filosofia “quanto menor, melhor”, o MINIX
originalmente não exigia disco rígido, trazendo-o assim para o alcance do
orçamento de muitos alunos(por mais que pareça surpreendente hoje, em meados da
década de 80 quando o MINIX nascia, os discos rígidos ainda eram uma cara
novidade), à medida que o MINIX crescia em funcionalidade e tamanho, acabou
chegando um momento em que um disco rígido era necessário,
mas fiel à filosofia MINIX, uma partição de 30 megabytes é suficiente. Em
contraste, alguns sistemas operacionais UNIX agora recomendavam, pelo menos,
uma partição de disco de 200MB como mínimo. Para o usuário médio que utiliza um
IBM PC, rodar o MINIX é semelhante a rodar o UNIX. Muitos programas básicos,
como cat, grep,ls, make e o shell estão presentes e executam as mesmas funções
que seus componentes no UNIX. Como o sistema operacional em si, todos esses
programas utilitários foram reescritos completamente a partir do zero pelo autor
e por seus alunos entre outras pessoas dedicadas. Logo depois que o MINIX foi
lançado, um grupo de discussão da USENET foi criado para discuti-lo. Em algumas
semanas o grupo já tinha 40.000 assinantes, parte dos quais queria adicionar um
grande número de recursos ao MINIX para torná-lo maior e melhor. Todos os dias
vários deles ofereciam sugestões, ideias e pequenos trechos de código. O autor
do MINIX resistiu com êxito a esse assalto por vários anos para manter o MINIX
suficientemente pequeno e limpo para os alunos entenderem-no. Gradualmente,
começou a tornar-se evidente o que ele realmente significava. Nesse ponto, um
estudante finlandês, Linus Torvalds, decidiu escrever um clone do MINIX
projetado para ser um sistema operacional carregado de recursos, em vez de uma
ferramenta educacional. Assim nascia o LINUX.
Hardware
requerido
O MINIX pode funcionar com quantidades baixas de memória e disco rígido. O MINIX 3 pode ser usado com apenas 16 MB de memória RAM e 50
MB de disco rígido, mas para instalação de outros software o recomendável é 600
MB de HD. É
possível testar pelo Live CD, funcionando sem necessidade de instalação no HD.
Funcionamento
Processos são entidades independentes, cada um com suas permissões de
acesso, e têm atribuídos propriedades como o id do usuário que o criou (UID) e
do grupo (GID). Grande parte de sua execução se processa em user-mode, quando o
processador não admite a execução de instruções privilegiadas, mas em certos
instantes (durante uma chamada de sistema), ele executa em modo núcleo para
conseguir o acesso a partes do hardware que de outra forma seriam inacessíveis.
Cada processo é identificado pelo seu process id (PID), que é simplesmente um
número inteiro.
Mais especificamente, do ponto de vista do sistema operacional, é uma
coleção de instruções (programa) mais os dados necessários à sua execução.
Armazenados juntamente com o processo estão o seu contexto, ou seja, o contador
de instruções, e o conjunto de todos os registradores da CPU. É
responsabilidade do sistema operacional gerenciar os processos do sistema, de
forma que, se um processo tenta ler ou escrever em um disco, por exemplo, este
processo ficará em estado waiting (suspenso) até que a operação seja completada.
Nesse ínterim, outro processo será habilitado a correr, desperdiçando assim
o mínimo do tempo da CPU, memória e
demais periféricos. O Minix suporta inclusive um procedimento de "escrita
retardada", quando escrevemos em algum arquivo. No momento da escrita, o
buffer que contém estes dados é simplesmente marcado como "sujo"
(dirty), e o sistema operacional escolhe o instante mais apropriado para
descarregar esse buffer no disco físico. Isso explica a necessidade que temos
de executar um procedimento de parada (shutdown ) antes de desligar a máquina,
para evitar que fiquem dados a serem descarregados (escritos) no disco rígido.
Introdução
Escolhemos o MINIX para desenvolver nossa pesquisa por se tratar de um
sistema operacional com enfoque no aprendizado. Tanto a versão 1 quanto a
versão 2 do MINIX foram desenvolvidas para ajudar estudantes a aprenderem e
principalmente entenderem todo o processo de funcionamento de um sistemas
operacionais.
O código por trás do MINIX é pequeno e claro, fazendo dele uma prática
ferramenta de estudo em um campo tão complexo. A versão mais recente, o MINIX
3, tenta manter os princípios das versões anteriores, mas também tenta ser mais
prático, como um sistema operacional moderno nos moldes do UNIX.
Visão Geral de Processos em MINIX
Diferente do UNIX, cujo Kernel é um programa monolítico e não dividido em
módulos, o MINIX é uma coleção de processos que se comunicam entre si e com
processos de usuário utilizando uma única primitiva de comunicação
interprocesso – a passagem de mensagem. Esse projeto proporciona uma estrutura
mais flexível e modula, torando fácil, por exemplo, substituir o sistema de
arquivos inteiro por um completamente diferente, sem nem mesmo precisar
recompilar o Kernel.
Conclusão
O MINIX é um
sistema operacional que atende a um pequeno nicho de usuários. É ideal para as
pessoas que querem menos funcionalidade do que o Linux e o BSD oferecem, mas
que querem continuar na mesma família. Também pode ser bastante útil para
aqueles que querem experimentar o uso de um microkernel. O certo é que o MINIX
vai continuar encontrando um lar em universidades, onde os alunos podem ter uma
experiência bastante prática ou tentando melhorar esse pequeno e funcional
sistema operacional.
Trabalho de Redes
Sistema Operacional de Redes.
Definição:
Um
Sistema Operacional de Redes é um conjunto de módulos que amplíam os sistemas
operacionais, complementando-os com um conjunto de funções básicas, e de uso
geral, que tornam transparente o uso de recursos compartilhados da rede.
O
computador tem, então, o Sistema Operacional Local (SOL) interagindo com o
Sistema Operacional de Redes (SOR), para que possam ser utilizados os recursos
de rede tão facilmente quanto os recursos na máquina local.
Em
efeito, o SOR coloca um redirecionador entre o aplicativo do cliente e o
Sistema Operacional Local para redirecionar solicitações de recursos da rede
para o programa de comunicação que vai buscar os recursos na própria rede.
O Modêlo
de Operação do Sistema Operacional de Rede é o modêlo Cliente / Servidor:
- Ambiente onde o
processamento da aplicação é partilhado entre um outro cliente (solicita
serviço) e um ou mais servidores (prestam serviços).
Os
módulos do SOR podem ser:
- Módulo Cliente do Sistema
Operacional (SORC)
- Módulo Servidor do Sistema
Operacional (SORS)
Os tipos
de arquiteturas para Sistemas Operacionais de Rede são:
- Peer-to-Peer
- Cliente-Servidor:
- Servidor
Dedicado
- Servidor
não Dedicado
Na
arquitetura Peer-to-Peer temos várias máquinas interligadas, cada uma com
serviços de Servidor e de Cliente na mesma máquina junto com o Sistema
Operacional Local.
Na
arquitetura Cliente-Servidor com Servidor Dedicado, temos uma máquina servidora
que não executa aplicativos locais.
Na
arquitetura Cliente-Servidor com Servidor não Dedicado, temos uma máquina
servidora que executa aplicativos locais, além de prover os serviços de
Servidor.
Ainda
podemos definir alguns tipos diferentes de servidores:
- Servidor de Arquivos.
- Servidor de Banco de Dados.
- Servidor de Impressão.
- Servidor de Comunicação.
- Servidor de Gerenciamento.
Servidores
de Arquivos são usados para distribuir arquivos (de dados e/ou programas
executáveis) em uma rede local. No passado eram usados para
"hospedar" os programas executáveis para uso por sistemas
"diskless" (sem disco rígido) ou com disco rígido pequeno. Servem
tambem para manter uma versão de um arquivo de dados para ser consultado por
todos os usuários na rede local.
Servidores
de Banco de Dados são usados para consulta e/ou cadastro de dados. A interface
de visualização pode ser proprietária, ou pode ser via interface web. Os bancos
de dados são de preferência tipo cliente/servidor.
Servidores
de Impressão, são máquinas ligadas na rede para gerenciar impressoras (lazer,
jato de tinta, matricial, etc.). A gerência pode incluir desde o simples roteamento
dos documentos para as impressoras, até o gerenciamento de cotas de papel por
usuário por período de tempo (dia, semana, mes).
Servidores
de Comunição, são maquinas usadas para distribuição de informações na rede.
Podem ser simples servidoras de correio eletrônico (e-mail) ou servidores web
e/ou ftp. Podem tambem ter modems para acesso remoto por parte dos usuários.
Servidores
de Gerenciamento são maquinas usadas na gerência da rede. Esse termo é bastante
amplo e pode ser aplicado tanto a maquinas que gerenciam o acesso de usuários à
rede (NT PDC, NT BDC, etc.) como maquinas que supervisionam tráfego na rede, ou
em alguns casos podem ser até os "firewalls" que gerenciam o acesso
aos diversos serviços.
Exemplos:
ATM e Gigabit Ethernet:
essas tecnologias por serem tecnologias novas, precisam ser aceitas pelo
mercado, por serem muito caras e porque a empresa pode não necessitar de tanta
tecnologia, como por exemplo, voz e videoconferência.
FDDI:
essa é uma tecnologia que trabalha com fibra óptica e acaba superando as
expectativas da empresa, tornando-se as vezes excessiva, cara e desnecessária,
além de ser recomendada para backbones. Devido a sua velocidade ser igual a do
Fast Ethernet (100 Mbps) e o Gigabit Ethernet ser a "continuação" do
Fast Ethernet, é melhor adotar o Fast Ethernet devido ao upgrade.
DBQD:
essa é uma tecnologia muito rápida (100 Mbps) e destina-se muito mais a redes
metropolitanas do que a redes locais.
O UNIX é um sistema
operacional de rede mais centrado para centros acadêmicos. Apesar de ser muito
bom em relação a segurança, gerenciamento de banco de dados e internet.
Uma solução que consideramos
ideal é de ter servidores NetWare e clientes NT. O NT como
cliente é muito mais amigável com o usuário do que o NetWare. Já o NetWare
trabalha muito melhor com alta taxa de tráfego de rede, é mais robusto, mais
seguro e trabalha melhor com um número maior de tarefas ao mesmo tempo.
Em se tratando de UNIX e NT, o NT é melhor em termos de segurança e
confiabilidade; o UNIX é melhor em termos de gerenciabilidade e são igualmente
bons em relação a escalabilidade.
Em se tratando de NT e NetWare, o NT é melhor em termos de gerenciabilidade,
escalabilidade, desempenho, segurança, tolerância a falha e relação de custo; o
NT é melhor em termos de desenvolvimento de aplicação.
No Brasil, 78% das empresas usam NT e 11% pensam em migrar para ele; do início
de 1997 até o início de 1998, o NT aumentou sua fatia no mercado mundial de 41
para 49% e o NetWare baixou de 31 para 21%; 58% das empresas consideram o NT
como o melhor sistema operacional para desenvolvimento de aplicações. O NetWare
pode ter perdido terreno, mas com o lançamento da versão 5.0, totalmente em
Java, demonstra o interesse da Novell em manter-se atualizada no ramo de redes.
Pode-se observar melhor isto, na teoria descrita acima, principalmente nos
tópicos referentes a comparações entre UNIX e NT e NetWare e NT.
STANCZAK,
Mark. Windows NT Server 5.0 vs. NetWare 5.0. Revista
PC MAGAZINE Brasil, Abril de
1998. p. 97-105.
TANENBAUM, Andrew S. Redes de Computadores. Tradução da 3ª
Edição. Editora Campus, Rio de
Janeiro, 1997, p. 122-161.
TAROUCO, Liane Margarida Rockenback. Redes de Computadores Locais e de Longa
Distância.
Editora McGraw-Hill, São Paulo, 1986, p. 122-147.
Rede
de Computadores:
Redes de computadores são
estruturas físicas (equipamentos) e lógicas (programas, protocolos) que
permitem que dois ou mais computadores possam compartilhar suas informações
entre si.
Imagine um computador
sozinho, sem estar conectado a nenhum outro computador: Esta máquina só terá
acesso às suas informações (presentes em seu Disco Rígido) ou às informações
que porventura venham a ele através de disquetes e Cds.
Quando um computador está
conectado a uma rede de computadores, ele pode ter acesso às informações que
chegam a ele e às informações presentes nos outros computadores ligados a ele
na mesma rede, o que permite um número muito maior de informações possíveis
para acesso através daquele computador.
Para conectar os
computadores em uma rede, é necessário, além da estrutura física de conexão
(como cabos, fios, antenas, linhas telefônicas, etc.), que cada computador
possua o equipamento correto que o fará se conectar ao meio de transmissão.
O equipamento que os
computadores precisam possuir para se conectarem a uma rede local (LAN) é a
Placa de Rede, cujas velocidades padrão são 10Mbps e 100Mbps (Megabits por
segundo).
Ainda nas redes locais,
muitas vezes há a necessidade do uso de um equipamento chamado HUB (lê-se
“Râbi”), que na verdade é um ponto de convergência dos cabos provenientes dos
computadores e que permitem que estes possam estar conectados. O Hub não é um
computador, é apenas uma pequena caixinha onde todos os cabos de rede,
provenientes dos computadores, serão encaixados para que a conexão física
aconteça.
Quando a rede é maior e não
se restringe apenas a um prédio, ou seja, quando não se trata apenas de uma
LAN, são usados outros equipamentos diferentes, como Switchs e Roteadores, que
funcionam de forma semelhante a um HUB, ou seja, com a função de fazer
convergir as conexões físicas, mas com algumas características técnicas (como velocidade
e quantidade de conexões simultâneas) diferentes dos primos mais “fraquinhos”
(HUBS).
As redes
de computadores podem ser classificadas como:
·
LAN (Rede
Local): Uma rede que liga computadores
próximos (normalmente em um mesmo prédio ou, no máximo, entre prédios próximos)
e podem ser ligados por cabos apropriados (chamados cabos de rede). Ex: Redes
de computadores das empresas em geral.
·
WAN (Rede
Extensa): Redes que se estendem além das
proximidades físicas dos computadores. Como, por exemplo, redes ligadas por
conexão telefônica, por satélite, ondas de rádio, etc. (Ex: A Internet, as
redes dos bancos internacionais, como o CITYBANK).
Aplicações Domésticas
|
Em
1977, Ken Olsen era presidente da Digital Equipment Corporation, então o
segundo maior fornecedor de computadores de todo o mundo (depois da IBM).
Quando lhe perguntaram por que a Digital não estava seguindo a tendência do
mercado de computadores pessoais, ele disse: "Não há nenhuma razão para
qualquer indivíduo ter um computador em casa". A história mostrou o
contrário, e a Digital não existe mais. Por que as pessoas compram
computadores para usar em casa? No início, para processamento de textos e
jogos; porém, nos últimos anos, esse quadro mudou radicalmente. Talvez agora
a maior motivação seja o acesso à Internet. Alguns dos usos mais
populares da Internet para usuários domésticos são:
1. Acesso a informações remotas.
2. Comunicação entre pessoas.
3. Entretenimento interativo.
4. Comércio eletrônico.
O acesso
a informações remotas tem várias formas. Ele pode significar navegar na World Wide Web para obter
informações ou apenas por diversão. As informações disponíveis incluem artes,
negócios, culinária, governo, saúde, história, passatempos, recreação,
ciência, esportes, viagens e muitos outros. A diversão surge sob tantas
formas que não podemos mencionar, e também se apresenta em outras formas que
é melhor não mencionarmos.
Muitos jornais
são publicados on-line e podem ser personalizados. Por exemplo, às vezes
é possível solicitar todas as informações sobre políticos corruptos, grandes
incêndios, escândalos envolvendo celebridades e epidemias, mas dispensar
qualquer notícia sobre esportes. Algumas vezes, é até mesmo possível
transferir os artigos selecionados por download para o disco rígido enquanto
você dorme ou imprimi-los na sua impressora pouco antes do café da manhã. À
medida que essa tendência continuar, ela causará desemprego maciço entre os
jovens entregadores de jornais, mas as empresas jornalísticas gostam dela,
porque a distribuição sempre foi o elo mais fraco na cadeia de produção
inteira.
A
próxima etapa além de jornais (e de revistas e periódicos científicos) é a
biblioteca digital on-line. Muitas organizações profissionais, como ACM (www.acm.org) e
IEEE Computer Society (www.computer.org), já têm muitos periódicos e anais de
conferências on-line. Outros grupos estão seguindo com rapidez essa
tendência. Dependendo do custo, tamanho e peso de notebooks com dimensões de
livros, os livros impressos poderão se tornar obsoletos. Os céticos devem
observar o efeito que a máquina de impressão teve sobre os manuscritos
medievais com iluminuras. Todas as aplicações anteriores envolvem
interações entre uma pessoa e um banco de dados remoto repleto de informações.
A segunda grande categoria de utilização de redes é a comunicação entre pessoas, basicamente a
resposta do Século XXI ao telefone do Século XIX. O correio eletrônico
(e-mail) já é usado diariamente por milhões de pessoas em todo o mundo e seu
uso está crescendo rapidamente. Em geral, ele já contém áudio e vídeo, além
de texto e imagens. O odor talvez demore um pouco mais.
Hoje em
dia, qualquer adolescente é fanático pela troca de mensagens instantâneas.
Esse recurso, derivado do programa talk do UNIX, em uso desde aproximadamente
1970, permite que duas pessoas digitem mensagens uma para a outra em tempo
real. Uma versão dessa idéia para várias pessoas é a sala de bate-papo (ou
chat room), em que um grupo de pessoas pode digitar mensagens que serão
vistas por todos.
Newsgroups
(grupos de notícias) mundiais, com discussões sobre todo tópico concebível,
já são comuns entre grupos seletos de pessoas, e esse fenômeno crescerá até
incluir a população em geral. O tom dessas discussões, em que uma pessoa
divulga uma mensagem e todos os outros participantes do newsgroup podem ler a
mensagem, poderá variar de bem-humorado a inflamado.
Diferentes
das salas de bate-papo, os newsgroups não são de tempo real, e as mensagens
são gravadas. Assim, por exemplo, quando alguém voltar das férias, todas as
mensagens publicadas durante esse período estarão bem guardadas, esperando
para serem lidas. Outro tipo de comunicação entre pessoas recebe
freqüentemente o nome de comunicação não hierárquica (peer-to-peer),
com o objetivo de distingui-la do modelo cliente/servidor (Parameswaran et
al., 2001). Nessa forma de comunicação, indivíduos que constituem um grupo
livre podem se comunicar com outros participantes do grupo, como mostra a
Figura. Em princípio, toda pessoa pode se comunicar com uma ou mais pessoas; não
existe nenhuma divisão fixa entre clientes e servidores.
Em um
sistema não hierárquico não existem clientes e servidores fixos
A
comunicação não hierárquica realmente alcançou o auge por volta de 2000 com um
serviço chamado Napster que, em seu pico, teve mais de 50 milhões de fãs de
música trocando todos os tipos de músicas, constituindo aquilo que
provavelmente foi a maior violação de direitos autorais em toda a história
registrada (Lam e Tan, 2001; Macedonia, 2000). A idéia era bastante simples.
Os associados registravam em um banco de dados central mantido no
servidor Napster a música que tinham em seus discos rígidos. Se queria uma
canção, cada associado verificava no banco de dados quem tinha a canção e ia diretamente
até o local indicado para obtê-la. Por não manter de fato nenhuma música
em suas máquinas, a Napster argumentou que não estava infringindo os direitos
autorais de ninguém. Os tribunais não concordaram e fecharam o site e a
empresa.
Porém, a geração seguinte de sistemas não hierárquicos eliminou o banco de
dados central, fazendo cada usuário manter seu próprio banco de dados
local, além de fornecer uma lista de outras pessoas próximas associadas
ao sistema. Um novo usuário pode então ir até qualquer associado para ver o
que ele tem e obter uma lista de outros associados, com a finalidade de
examinar outras músicas e outros nomes. Esse processo de pesquisa pode ser
repetido indefinidamente, até constituir em um local um grande banco de dados
do que existe fora desse local. Essa atividade seria tediosa para as pessoas,
mas é especialmente adequada para computadores.
Também existem aplicações legais para comunicação não hierárquica. Por
exemplo, aficionados que compartilham músicas de domínio público ou amostras
de faixas liberadas por novos conjuntos musicais para fins de publicidade,
famílias que compartilham fotografias, filmes e informações sobre a árvore
genealógica, e adolescentes que participam de jogos on-line com várias
pessoas. De fato, uma das aplicações mais populares de toda a Internet, o correio
eletrônico, é inerentemente não hierárquica. Espera-se que essa
forma de comunicação venha a crescer consideravelmente no
futuro.
O crime eletrônico não se restringe a infrações de direitos autorais. Outra
área agitada é a dos jogos de apostas eletrônicos. Os computadores têm
simulado vários tipos de atividades durante décadas. Por que não simular
máquinas caça-níqueis, jogos de roleta, mesas de vinte-e-um e outros
equipamentos de jogos? Bem, porque isso é ilegal em muitos países. O grande
problema é que o jogo é legal em muitos outros lugares (na Inglaterra, por
exemplo) e os donos de cassinos
perceberam o potencial para jogos de apostas pela Internet. Então, o que
acontecerá se o jogador e o cassino estiverem em países diferentes, com leis
conflitantes? Essa é uma boa pergunta.
Outras aplicações orientadas a comunicações incluem a utilização da Internet
para realizar chamadas telefônicas, além de videotelefonia e rádio pela
Internet, três áreas de rápido crescimento. Outra aplicação é o ensino à
distância (telelearning), que significa freqüentar aulas às 8 da manhã sem a
inconveniência de ter de sair da cama. No final das contas, o uso de redes
para aperfeiçoar a comunicação entre os seres humanos pode se mostrar mais
importante que qualquer dos outros usos.
Nossa
terceira categoria é o entretenimento,
uma indústria enorme e que cresce mais e mais a cada dia. A aplicação
fundamental nesse caso (aquela que deverá orientar todas as outras) é o
vídeo por demanda. Dentro de aproximadamente uma década talvez seja
possível selecionar qualquer filme ou programa de televisão, qualquer que
seja a época ou país em que tenha sido produzido, e exibi-lo em sua tela no
mesmo instante. Novos filmes poderão se tornar interativos e ocasionalmente o
usuário poderá ser solicitado a interferir no roteiro (Macbeth deve matar
Duncan ou aguardar o momento propício?), com cenários alternativos para todas
as hipóteses. A televisão ao vivo também poderá se tornar interativa, com os
telespectadores participando de programas de perguntas e respostas,
escolhendo entre concorrentes e assim por diante. Por outro lado, talvez a
aplicação mais importante não seja o vídeo por demanda, mas sim os jogos.
Já temos jogos de simulação em tempo real com vários participantes, como os
de esconder em um labirinto virtual, e simuladores de vôo em que os jogadores
de uma equipe tentam abater os jogadores da equipe adversária. Se os jogos
forem praticados com óculos de proteção e imagens tridimensionais de
qualidade fotográfica e movimentos em tempo real, teremos uma espécie de
realidade virtual compartilhada em escala mundial.
Nossa quarta categoria é
o comércio eletrônico no sentido mais
amplo do termo. A atividade de fazer compras em casa já é popular e permite
ao usuário examinar catálogos on-line de milhares de empresas. Alguns
desses catálogos logo oferecerão a possibilidade de obter um vídeo
instantâneo sobre qualquer produto com um simples clique no nome do produto.
Após a compra eletrônica de um produto, caso o cliente não consiga
descobrir como usá-lo, poderá ser consultado o suporte técnico on-line.
Outra área em que o comércio eletrônico já é uma realidade é o acesso a
instituições financeiras. Muitas pessoas já pagam suas contas, administram
contas bancárias e manipulam seus investimentos eletronicamente. Sem dúvida,
isso crescerá à medida que as redes se tornarem mais seguras.
Uma área que praticamente ninguém previu é a de brechós eletrônicos
(e-brechó?). Leilões on-line de objetos usados se tornaram uma indústria
próspera. Diferente do comércio eletrônico tradicional, que segue o modelo
cliente/servidor, os leilões on-line se parecem mais com um sistema não
hierárquico, uma espécie de sistema de consumidor para consumidor. Algumas
dessas formas de comércio eletrônico utilizam pequenas abreviações
baseadas no fato de que "to" e "2" têm a mesma pronúncia
em inglês. As mais populares estão relacionadas na Figura.
Algumas
formas de comércio eletrônico
|
Abreviação
|
Nome
Completo
|
Exemplo
|
|
B2C
|
Business
-to-Consumer
|
Pedidos
de livros on-line
|
|
B2B
|
Business-to-Business
|
Fabricante
de automóveis solicitando pneus a um fornecedor
|
|
G2C
|
Government-to-consumer
|
Governo
distribuindo eletronicamente formulários de impostos
|
|
C2C
|
Consumer-to-consumer
|
Leilões
on-line de produtos usados
|
Sem
dúvida a diversidade de usos de redes de computadores crescerá rapidamente no
futuro, e é provável que esse crescimento se dê por caminhos que ninguém é
capaz de prever agora. Afinal, quantas pessoas em 1990 previram que o fato de
adolescentes digitarem tediosamente pequenas mensagens de texto em telefones
celulares enquanto viajavam de ônibus seria uma imensa fábrica de dinheiro
para as empresas de telefonia 10 anos depois? No entanto, o serviço de
mensagens curtas (short message) é muito lucrativo.
As redes de computadores podem se tornar imensamente importantes para pessoas
que se encontram em regiões geográficas distantes, dando a elas o mesmo
acesso a serviços que é oferecido às pessoas que vivem em uma grande cidade.
O ensino à distância pode afetar de forma radical a educação; as
universidades poderão ser nacionais ou internacionais. A telemedicina só
agora está começando a se desenvolver (por exemplo, com o monitoramento
remoto de pacientes), mas pode vir a ser muito mais importante. Porém, a
aplicação fundamental poderá ser algo comum, como usar a câmera da Web
(webcam) no refrigerador para verificar se é preciso comprar leite no caminho
do trabalho para casa.
|
Aplicações Comerciais
|
Muitas
empresas têm um número significativo de computadores. Por exemplo, uma
empresa pode ter computadores se parados para monitorar a produção, controlar
os estoques e elaborar a folha de pagamento. Inicialmente, cada um desses
computadores funcionava isolado dos outros mas, em um determinado momento, a
gerência deve ter decidido conectá-los para poder extrair e correlacionar
informações sobre a empresa inteira. Em termos um pouco mais genéricos, a
questão aqui é o compartilhamento de recursos,
e o objetivo é tornar todos os programas, equipamentos e especialmente dados
ao alcance de todas as pessoas na rede, independente da localização física do
recurso e do usuário.
Um
exemplo óbvio e bastante disseminado é um grupo de funcionários de um escritório
que compartilham uma impressora comum. Nenhum dos indivíduos realmente
necessita de uma impressora privativa, e uma impressora de grande capacidade
conectada em rede muitas vezes é mais econômica, mais rápida e de mais fácil
manutenção que um grande conjunto de impressoras individuais. Porém, talvez
mais importante que compartilhar recursos físicos como impressoras, scanners
e gravadores de CDs, seja compartilhar informações.
Toda
empresa de grande e médio porte e muitas empresas pequenas têm uma dependência
vital de informações computadorizadas. A maioria das empresas tem registros
de clientes, estoques, contas a receber, extratos financeiros, informações
sobre impostos e muitas outras informações on-line. Se todos os computadores
de um banco sofressem uma pane, ele provavelmente não duraria mais de cinco
minutos. Uma instalação industrial moderna, com uma linha de montagem
controlada por computadores, não duraria nem isso.
Hoje,
até mesmo uma pequena agência de viagens ou um a firma jurídica com três
pessoas depende intensamente de redes de computadores para permitir aos seus
funcionários acessarem informações e documentos relevantes de forma
instantânea.
No mais
simples dos termos, é possível imaginar que o sistema de informações de uma
empresa consiste em um ou mais bancos de dados e em algum número de
funcionários que precisam acessá-los remotamente. Nesse modelo, os dados são armazenados
em poderosos computadores chamados servidores. Com freqüência, essas
máquinas são instaladas e mantidas em um local central por um
administrador de sistemas. Em contraste, os funcionários têm em suas
escrivaninhas máquinas mais simples, chamadas clientes, com as quais
eles acessam dados remotos, por exemplo, para incluir em planilhas
eletrônicas que estão elaborando. (Algumas vezes, faremos referência ao
usuário humano da máquina cliente como o "cliente", mas deve ficar
claro a partir do contexto se estamos nos referindo ao computador ou a seu
usuário.) As máquinas clientes e servidores são conectadas entre si por
uma rede. Observe que mostramos a rede como uma simples elipse, sem
qualquer detalhe. Utilizaremos essa forma quando mencionarmos uma rede no
sentido abstrato. Quando forem necessários mais detalhes, eles serão
fornecidos.
Uma
rede com dois cliente e um servidor
Todo
esse arranjo é chamado modelo cliente/servidor. Ele é amplamente usado
e constitui a base da grande utilização da rede. Ele é aplicável quando o
cliente e o servidor estão ambos no mesmo edifício (por exemplo, pertencem à
mesma empresa), mas também quando estão muito distantes um do outro. Por
exemplo, quando uma pessoa em sua casa acessa uma página na World Wide
Web, é empregado o mesmo modelo, com o servidor da Web remoto fazendo o
papel do servidor e o computador pessoal do usuário sendo o cliente. Sob a
maioria das condições, um único servidor pode cuidar de um grande número
de clientes.
Se
examinarmos o modelo cliente/servidor em detalhes, veremos que há dois
processos envolvidos, um na máquina cliente e um na máquina servidora. A
comunicação toma a forma do processo cliente enviando uma mensagem pela rede
ao processo servidor. Então, o processo cliente espera por uma mensagem em
resposta. Quando o processo servidor recebe a solicitação, ele executa o
trabalho solicitado ou procura pelos dados solicitados e envia de volta uma
resposta. Essas mensagens são mostradas na Figura.
O
modelo cliente/servidor envolve solicitações e respostas
Um segundo
objetivo da configuração de uma rede de computadores está relacionado às pessoas, e não às
informações ou mesmo aos computadores. Uma rede de computadores pode oferecer
um eficiente meio de comunicação entre
os funcionários. Agora, virtualmente toda empresa que tem dois ou mais
computadores tem o recurso de correio eletrônico (e-mail), que os
funcionários utilizam de forma geral para suprir uma grande parte da
comunicação diária. De fato, os funcionários trocam mensagens de e-mail sobre
os assuntos mais corriqueiros, mas grande parte das mensagens com que as
pessoas lidam diariamente não tem nenhum significado, porque os chefes
descobriram que podem enviar a mesma mensagem (muitas vezes sem qualquer
conteúdo) a todos os seus subordinados, bastando pressionar um botão.
Contudo,
o e-mail não é a única forma de comunicação otimizada que as redes de
computadores tornaram possível. Com uma rede, é fácil duas ou mais pessoas
que trabalham em locais muito distantes escreverem juntas um relatório.
Quando um trabalhador faz uma mudança em um documento on-line, os outros
podem ver a mudança imediatamente, em vez de esperarem vários dias por uma
carta. Tal aceleração facilita a cooperação entre grupos de pessoas
distantes entre si, o que antes era impossível.
Outra
forma de comunicação auxiliada pelo computador é a videoconferência. Usando
essa tecnologia, funcionários em locais distantes podem participar de uma
reunião, vendo e ouvindo uns aos outros e até mesmo escrevendo em um
quadro-negro virtual compartilhado. A videoconferência é uma ferramenta
eficiente para eliminar o custo e o tempo anteriormente dedicado às
viagens. Algumas vezes, dizemos que a comunicação e o transporte estão
disputando uma corrida, e a tecnologia que vencer tornará a outra obsoleta.
Um terceiro objetivo para um número cada vez maior de empresas é
realizar negócios eletronicamente com outras
empresas, em especial fornecedores e clientes. Por exemplo,
fabricantes de automóveis, aeronaves e computadores, entre outros, compram
subsistemas de diversos fornecedores, e depois montam as peças. Utilizando
redes de computadores, os fabricantes podem emitir pedidos eletronicamente,
conforme necessário. A capacidade de emitir pedidos em tempo real (isto é,
conforme a demanda) reduz a necessidade de grandes estoques e aumenta a
eficiência.
Um
quarto objeto que está começando a se tornar mais importante é o de realizar negócios com consumidores pela Internet.
Empresas aéreas, livrarias e lojas de discos descobriram que muitos clientes
apreciam a conveniência de fazer compras em casa. Conseqüentemente, muitas
empresas fornecem catálogos de suas mercadorias e serviços on-line e emitem
pedidos on-line. Espera-se que esse setor cresça rapidamente no futuro. Ele é
chamado comércio eletrônico (ecommerce).
|
Classificação das Redes
1.
Classificação das Redes de Computadores Quando tratamos de Rede de Computadores
existe uma classificação mais frequente que baseia-se na área – geográfica ou
organizacional.
2. Redes
Locais – LAN Trata-se de um conjunto de computadores que pertencem a uma mesma
organização e que estão ligados entre eles numa pequena área geográfica (Sala
de Aula, Casa, Pequenas Empresas)
3. Redes
Locais – LAN Local Area Networks - LANs Distância entre os processadores: 1 m a
poucos km. Taxa de erros: baixa São normalmente de propriedade privada.
Exemplos de tecnologias empregadas : Ethernet, Token Ring e ATM (Asynchronous
Transfer Mode).
4. Redes
Metropolitanas– MAN Permitem a interligação de redes e equipamentos em uma área
metropolitana ( locais situados em diversos pontos de uma cidade).
5. Redes
Metropolitanas– MAN Metropolitan Area Networks – MANs. Distância entre os
processadores: 10 Km (cidade). Taxa de erros (baixa). Estão se confundindo com
as LANs. Exemplos de tecnologias empregadas: X.25, Frame Relay e ATM.
6. Redes
Geograficamente Distribuídas – WAN É uma rede de longa distância, que permite a
interligação de redes locais, metropolitanas e equipamentos de rede, numa
grande área geográfica (país, continente, etc).
7. Redes
Geograficamente Distribuídas – WAN Wide Area Networks - WANs Distância entre os
processadores: sem limite. Taxa de erros: maior do que nas LANs e WANs Exemplos
de tecnologias empregadas: X.25, Frame Relay e ATM.
8. Redes
pessoais – PANs São a s redes de área pessoal, sem fios permitem um intercâmbio
de comunicação e informação entre computadores, PDAs, impressoras, telefones
móveis e outros dispositivos numa área de alcance limitada
9. Redes
pessoais – PANs Personal Area Networks – PANs Alcance muito pequeno. Sem-fio
(wireless), com taxas não muito altas. Visava substituir os cabos de
interligação. Outras aplicações: Sincronização de PDAs, fones. Exemplos: redes
Bluetooth.
10.
Outras Redes SAN ( Storage Area Networks ) RAN ( Regional Area Netwoks ) CAN (
Campus Area Netwoks ) WMAN ( Wireless Metropolitan Area Networks ) WWAN (
Wireless Wide Area Netwoks )
Classificação das Redes Sem Fio
WPAN
(Wireless Personal Area
Network)
WPAN está normalmente associada ao Bluetooth (antigamente ao
IR). Pode ser vista com a interação entre os dispositivos móveis de um
utilizador. A WPAN é projetada pra pequenas distâncias, baixo custo e baixas
taxas de transferência.
Exemplo de WPAN
WLAN (Wireless Local Area Network)
Wireless LAN ou WLAN, são uma rede local que usa ondas de
rádio para fazer uma conexão Internet ou entre uma rede, ao contrário da rede
fixa ADSL ou conexão-TV, que geralmente usa cabos. WLAN já é muito importante
como opção de conexão em muitas áreas de negócio. Inicialmente os WLAN’s assim
distante do público em geral foi instalado nas universidades, nos aeroportos, e
em outros lugares públicos principais. A diminuição dos custos do equipamento
de WLAN trouxe-o também a muitos particulares. Os componentes de WLAN são agora
baratos o bastante para ser usado nas horas de repouso e podem ser usados para
compartilhar uma conexão Internet com a família inteira.
Entretanto a falta da perícia em ajustar tais sistemas
significa freqüentemente que seu vizinho compartilha também de sua conexão
Internet, às vezes sem você (ou eles) se darem conta. A freqüência em que
802.11b se opera é 2.4GHz, a que pode conduzir interferência com muitos
telefones sem fio.
WMAN (Wireless Metropolitan Area Network)
WMAN ou Redes Metropolitanas Sem Fio. Esse escopo se refere a
redes metropolitanas: redes de uso corporativo que atravessam cidades e
estados. Essa conexão é utilizada na prática entre os provedores de acesso e
seus pontos de distribuição. O WiMax (padrão 802.16) é um dos últimos
padrões de banda larga para rede MAN definido pelo IEEE, em certo aspecto muito
similar ao padrão Wi-FI (IEEE 802.11) já muito difundido. O padrão WiMAX tem
como objetivo estabelecer a parte final da infra-estrutura de conexão de banda-larga
oferecendo conectividade para mais diversos fins: por exemplo, uso doméstico, hotspot e empresarial.
Exemplo de WMAN
WWAN (Wireless Wide Area Network)
As redes WWAN são basicamente as tradicionais tecnologias do
nosso famoso Telefone Celular de voz e alguns serviços de dados (Wireless Data Services).
Temos as seguintes tecnologias nessa categoria começando pela sigla TDMA que
vem do inglês Time Division
Multiple Access, que quer dizer "Acesso Múltiplo por Divisão
de Tempo". O TDMA é um sistema de celular digital que funciona dividindo
um canal de freqüência em até seis intervalos de tempo distintos. Cada usuário
ocupa um espaço de tempo específico na transmissão, o que impede problemas de
interferência.
Exemplo de WWAN
CAN (Campus
Area Network) – Rede que interliga
computadores situados em diferentes edificações de um mesmo complexo
institucional (Ex. Universidades, Condomínios, etc).
SAN (Storage Area Network) – Regularmente
chamadas de Redes de armazenamento, têm como objetivo a ligação entre vários
computadores e dispositivos de storage
(armazenamento) em uma área limitada. Considerando que é
fundamental que estas redes têm grandes débitos (rápido acesso à informação),
utilizam tecnologias diferenciadas como por exemplo Fiber Channel.
RAN (Regional
Area Network) é uma rede de
uma região geográfica específica. Caracterizadas pelas conexões de alta
velocidade utilizando cabo de fibra óptica, RANs são maiores que as redes LAN e
MAN, mas são menores que as Redes WAN. Num sentido mais restrito as Redes RANs
são consideradas uma sub-classe de redes MAN.
Modos de Operação
Redes Ad-hoc
Exemplo de Rede
Ad Hoc
Existe um modo de interligar
computadores diretamente sem a utilização de um ponto de acesso (Access Point), e para esta
ligação é dado o nome de “ad
hoc”, que é semelhante a uma ligação de um cabo cruzado (crossover) de Ethernet.
Este tipo de conexão é inteiramente privado, onde um computador da rede se
torna o controlador dela (ponto de acesso de software). É muito utilizado para
a transferência de arquivos entre computadores na falta de outro meio. Apesar
de ser um método para compartilhar arquivos pode também ser utilizado para
compartilhamento de internet, através da configuração de um computador na rede,
responsável pelo gerenciamento do compartilhamento (ENGST e FLEISHMAN, 2005).
Redes Infra-estruturadas
Uma rede infra-estruturada é
composta por um AP (Access
Point ou Ponto de Acesso) e clientes conectados a ele. O AP realiza
um papel semelhante a um HUB ou roteador, fazendo assim uma ponte entre a rede
cabeada e a rede sem fio. A ligação física entre ambas é feita de modo simples,
bastando apenas conectar um cabo Ethernet da rede cabeada convencional ao ponto
de acesso, onde este permitirá o acesso sem fio de seus clientes (ENGST E FLEISHMAN,
2005).
Exemplo de Rede
Infra-estruturada
Conclusões
As redes locais sem fio já são uma realidade em vários ambientes de
redes, principalmente nos que requerem mobilidade dos usuários.As aplicações
são as mais diversas e abrangem desde aplicações médicas, por exemplo, visita a
vários pacientes com sistema portátil de monitoramento, até ambientes de
escritório ou de fábrica.Apesar das limitações de cobertura geográfica,
utilizando-se a arquitetura de sistemas de distribuição, pode-se aumentar a abragência
da rede sem fio, fazendo uso de vários sistemas de distribuição interconectados
via rede com fio, num esquema de roaming
entre microcéclulas, semelhante a um sistema de telefonia celular convencional
Padrões de Rede Sem Fio
O padrão 802.11a é um padrão que trabalha na freqüência de 5
GHz, e surgiu em 1999, porém não é muito utilizado nos dias atuais, por não
existirem muitos dispositivos fabricados que utilizem esta tecnologia (DUARTE,
2003). Os equipamentos do padrão 802.11a começaram a surgir em 2002, logo após
o padrão 802.11b.
Isso ocorreu porque o espectro em que o padrão 802.11a
deveria operar ainda não estava disponível, bem como algumas tecnologias para
seu desenvolvimento (ENGST e FLEISHMAN, 2005).
O IEEE é uma associação profissional, cuja missão é
desenvolver padrões técnicos com base no consenso de fabricantes, ou seja,
definem como se dará a comunicação entre dispositivos clientes de rede. Com o
passar dos tempos foram criados vários padrões, onde o que se destaca e melhor
se desenvolveu foi o 802.11 (também conhecido como Wi-Fi - Wireless Fidelity – Fidelidade
sem fio) (RUFINO, 2005).
A seguir serão mostradas as tecnologias de rede sem fio mais
comuns utilizadas pelas empresas no contexto atual, bem como algumas que ainda
estão em fase de desenvolvimento.
Padrão 802.11a
O padrão 802.11a é um padrão que trabalha na freqüência de 5
GHz, e surgiu em 1999, porém não é muito utilizado nos dias atuais, por não
existirem muitos dispositivos fabricados que utilizem esta tecnologia (DUARTE,
2003). Os equipamentos do padrão 802.11a começaram a surgir em 2002, logo após
o padrão 802.11b. Isso ocorreu porque o espectro em que o padrão 802.11a
deveria operar ainda não estava disponível, bem como algumas tecnologias para
seu desenvolvimento (ENGST e FLEISHMAN, 2005).
RUFINO (2005), ENGST e FLEISHMAN (2005) afirmam que as
principais características do padrão 802.11a são as seguintes:
- O aumento de
sua velocidade para utilização em 54 Mbit/s ou aproximadamente 25 Mbit/s
de throughput
real (108 Mbit/s em modo turbo), porém podendo ser utilizado para
transmissões em velocidades mais baixas;
- Trabalha na
faixa de 5 GHz, com pouquíssimos concorrentes, porém o alcance é reduzido,
mas com melhores protocolos que o 802.11b;
- A quantidade
de clientes conectados pode chegar a 64;
- Possui 12
canais não sobrepostos, que permite que os pontos de acessos possam cobrir
a área um do outro sem causar interferências ou conflitos.
A sua principal desvantagem é a incompatibilidade com o
padrão 802.11b, que já possui uma grande plataforma instalada no cenário
tecnológico atual, pois ambos os padrões utilizam faixas de freqüências
diferentes (ENGST e FLEISHMAN, 2005).
Padrão 802.11b
Em meados de 1999 a 2001, surgiu o
Padrão 802.11b, que hoje é chamado por ENGST e FLEISHMAN (2005), de “O Rei
Dominante”. Isso devido o motivo de ser o mais popular e com a maior base instalada
com uma vasta gama de produtos e ferramentas de administração disponíveis no
mercado atual. O 802.11b utiliza o espalhamento espectral por seqüência direta
(DSSS) para receber e transmitir os dados a uma velocidade máxima de 11
megabits por segundo, porém esta não é sua velocidade real, pois estes 11
Mbit/s incluem todo o overhead
(sobrecarga) de rede para o início e o fim dos pacotes. A taxa real
pode variar de acordo com as configurações do equipamento e do espectro em que
se encontra, porém pode variar entre 4 a 7 Mbit/s aproximadamente.
Este sub padrão do 802.11 opera na
faixa de freqüência de 2.4 GHz e trabalha basicamente em cinco velocidades:
11Mbit/s, 5.5 Mbit/s, 2 Mbit/s, 1 Mbit/s e 512 kbit/s (variando entre 2,400 GHz
a 2,4835 GHz aproximadamente), suportando no máximo 32 clientes conectados.
(RUFINO, 2005).
Padrão 802.11g
Surgiu em meados de 2002 como sendo a tecnologia que possui
uma combinação ideal para utilização, a mais rápida e compatível no mercado de
redes sem fio, pois trabalha com uma taxa de transferência de até 54 Mbit/s e
na mesma freqüência do padrão 802.11b. Por existirem muitas divergências
políticas para a adoção do 802.11a, o IEEE demorou mais de três anos para
adotar definitivamente o padrão 802.11g, ocorrendo em 12 de junho de 2003
(ENGST e FLEISHMAN, 2005, RUFINO, 2005)
O padrão 802.11g pode se tornar um pouco mais lento que o
802.11a em uma mesma situação, mas isto é devido ao balanceamento de carga de
transmissão com o 802.11b. Esta compatibilidade não é nenhum ponto opcional
para o fabricante, ou seja, não cabe a ele determinar se no desenvolvimento de
qualquer produto da linha 802.11g colocará uma compatibilidade com o 802.11b,
este é uma parte obrigatória da especificação do padrão (ENGST e FLEISHMAN,
2005).
Suas principais características são:
- Velocidades
que podem chegar a atingir 54 Mbit/s;
- Compatibilidade
total com os equipamentos do protocolo 802.11b, pois ambos operam na
freqüência de 2,4 GHz.
Padrão 802.11n
Este padrão ainda está em fase de definição tendo como sua
principal finalidade o aumento da taxa de transmissão dos dados, algo próximo
dos 100 a 500 Mbit/s. Este padrão também é conhecido como WWiSE (World Wide Spectrum Efficiency).
Paralelamente objetiva-se alcançar um elevado aumento na área de cobertura do
sinal. O padrão 802.1n pode operar com canais de 40 MHz, e manter compatibilidade
com os existentes atualmente que trabalham em 20 Mhz, porém suas velocidades
oscilam em torno de135 Mbit/s (RUFINO, 2005).
Padrão 802.16
(WiMax)
Sua principal utilização e finalidade de criação é alcançar
longas distâncias utilizando ondas de rádio, pois a utilização de cabos de rede
para implementação de uma rede de dados de alta velocidade a uma distância
longa, seja ela entre cidades, em uma residência ou em uma área rural, por
exemplo, pode custar muito caro e estar ao alcance financeiro de poucos. Este
padrão de rede se refere a uma WMAN, já citada em conceitos anteriores, que
liga grandes distâncias em uma rede de banda larga. Visando desenvolver um
padrão para atender esta demanda, o IEEE no seu papel de precursor da
padronização, cria o padrão 802.16 (ENGST e FLEISHMAN, 2005).
Sua primeira especificação trabalhava na faixa de freqüência
de 10 a 66 GHz, ambas licenciadas como não licenciadas. Porém, com um pouco
mais de trabalho surgiu recentemente o 802.16a, que abrange um intervalo de utilização
compreendido entre 2 e 11 GHz, incluindo assim a freqüência de 2,4 GHz e 6 GHz
dos padrões 802.11b, 802.11g e 802.11a. A sigla utilizada para denominar o
padrão 802.16 é o WiMax, que por sua vez, diferentemente de Wi-Fi, possui um
significado real: Wireless
Interoperability for Microwave Access (Interoperabilidade sem fio
para acesso micro ondas), criado pela Intel e outras empresas líderes na
fabricação de equipamentos e componentes de comunicação. A velocidade de
transmissão de uma rede WiMax pode chegar até 134,4 Mbit/s em bandas
licenciadas e até 75 Mbit/s em redes não licenciadas. (ENGST e FLEISHMAN, 2005,
CÂMARA e SILVA, 2005).
Padrão 802.1x
Este tipo de padrão se refere a dois pontos de segurança
fundamentais em uma rede sem fio, a Privacidade e a Autenticação. Na visão de
autenticação, o padrão adota ao nível de porta, onde esta porta se refere a um
ponto de conexão a uma LAN, podendo esta conexão ser física ou lógica
(utilizando-se de dispositivos sem fio e AP). O padrão 802.1x surgiu para
solucionar os problemas com a autenticação encontrados no 802.11. Sua
implementação pode ser feita através de software ou de hardware, utilizando-se
dispositivos específicos para esta função, oferecendo interoperabilidade e
flexibilidade para a integração de componentes e funções (SILVA e DUARTE,
2005).
Seu modo de funcionamento é bastante simples, porém
eficiente. Consiste nada mais nada menos que colocar um “porteiro” para
controlar o acesso à rede. Seu trabalho é evitar que indivíduos não autorizados
acessem a rede, e para isso ele fornece credenciais aos clientes que podem ter
acesso à mesma contendo um simples nome de usuário e uma senha ou um sistema de
controle mais rigoroso que verifica a autenticidade de uma assinatura digital,
por exemplo. Todo seu funcionamento é composto por três elementos: o cliente
que pode ser chamado de solicitante, um ponto de acesso à rede que será
responsável pela autenticação (o porteiro), e um servidor de autenticação, que
conterá um banco de dados com as informações necessárias para a autenticação do
cliente (ENGST e FLEISHMAN, 2005).
Portanto é simples de entender seu modo de autenticação. O
cliente solicita a entrada na rede para o porteiro (ponto de acesso) e este por
sua vez envia as informações recebidas do cliente até o servidor de
autenticação, que retornará se as informações são válidas ou não. Caso as
informações sejam corretas, o porteiro fornece o acesso à rede para o cliente
que solicitou.
Arquitetura
de Redes
Uma Arquitetura de Aplicação define a estrutura de comunicação entre os
utilizadores da aplicação. Existem basicamente três tipos de arquitetura:
Cliente-Servidor, Peer-to-Peer e uma arquitetura híbrida, que é uma mescla das
outros duas. Ao contrario de uma arquitetura de rede, que é fixa, ou seja,
provê um conjunto específico de serviços as aplicaçõoes, a arquitetura de
aplicação deve ser escolhida pelo desenvolvedor da aplicação, determinando o
modo que a aplicação vai se comportar nos sistemas finais em uma rede.
Com essa classificação segundo a arquitetura (cliente-servidor, P2P ou
híbrida) pode-se entender melhor como se comportam as aplicações em uma rede.
Em qualquer uma dessas arquiteturas, uma aplicação se comunica através de pares
de processos, onde um é rotulado cliente e outro servidor. Mesmo em uma
aplicação do tipo P2P, o par que solicita um arquivo de outra máquina, é
denominado cliente, e o outro que fornece é o servidor. Cliente e Servidor
Este modelo praticamente ocupava a única possibilidade e acabava
assumindo como unanimidade o posto de arquitetura de aplicação, isso ocorria
devido a computadores poderosos, com muita memória, serem muito caros. Com
isso, a tendência era que existissem computadores potentes que centralizassem
esses efeitos, por isso MainFrames eram utilizados para armazenar dados de
clientes para fazer operações remotas.
Na atualidade, apesar do avanço da tecnologia, trazendo computadores
pessoais com maior possibilidade de processamento e de memória, com custo
baixo, esse modelo ainda se apresenta com muita força e aparentemente terá
forças para continuar por muito tempo ainda.
Cliente-Servidor
No modelo de arquitetura Cliente-Servidor, existem dois processos envolvidos,
um no host cliente e um outro no host servidor. A comunicação acontece quando
um cliente envia uma solicitação pela rede ao processo servidor, e então o
processo servidor recebe a mensagem, e executa o trabalho solicitado ou procura
pelos dados requisitados e envia uma resposta de volta ao cliente, que estava
aguardando. Nesta arquitetura o servidor tem uma aplicação que fornece um
determinado serviço e os clientes tem aplicações que utilizam este serviço. Uma
característica desta arquitetura, é que um cliente não se comunica com outro
cliente, e o servidor, que tem um endereço fixo, esta sempre em funcionamento.
Quase sempre um único servidor é incapaz de suportar as requisições de todos os
clientes, devido a isso, na maioria dos casos são utilizados vários servidores
que constituem um servidor virtual (server farm). Um exemplo claro de aplicação
Cliente-Sevidor é a comunicação entre um browser, que é usado para visualizar
páginas da internet, em um servidor web. Neste tipo de aplicação o cliente
(browser) e o servidor (servidor web) comunicam-se trocando mensagens através
do protocolo HTTP.
Peer-to-Peer
A arquitetura P2P (Peer-to-Peer) consiste em uma comunicação direta
entre os clientes, não existe nenhuma divisão fixa entre cliente e servidor.
Cada par (peer) ativo requisita e fornece dados a rede, desta forma não existe
a dependência do servidor, isso aumenta significativamente a largura de banda e
a redução de recursos. Esse tipo de arquitetura é utilizado principalmente por
aplicações de compartilhamento de conteúdo, como arquivos contendo áudio,
vídeo, dados ou qualquer coisa em formato digital. Outras aplicações orientadas
a comunicações de dados, como a telefonia digital, videotelefonia e rádio pela
internet também utilizam esta arquitetura. Como exemplo podemos citar o
protocolo BitTorrent que utiliza a arquitetura peer-to-peer para
compartilhamento de grandes quantidades de dados. Neste exemplo um cliente é
capaz de preparar e transmitir qualquer tipo de ficheiro de dados através de uma
rede, utilizando o protocolo BitTorrent.
Um peer (par) é qualquer computador que esteja executando uma instância
de um cliente. Para compartilhar um arquivo ou grupo de arquivos, um nó
primeiro cria um pequeno arquivo chamado "torrent" (por exemplo,
Meuarquivo.torrent). Este arquivo contém metadados sobre os arquivos a serem
compartilhados e sobre o tracker, que é o computador que coordena a
distribuição dos arquivos. As pessoas que querem fazer o download do arquivo
devem primeiro obter o arquivo torrent, e depois se conectar ao tracker, que
lhes diz a partir de quais outros pares que se pode baixar os pedaços do
arquivo.
Híbrida
Com uma pesquisa realizada pela empresa Xerox, foi detectado que pelo
menos 70% dos usuários de P2P não compartilhavam arquivo, enquanto apenas 1%
compartilhavam 50% destes, ou seja, a teoria que se tinha de “divisão de
trabalho” pelos clientes, não valia na prática. Para isso então, buscou-se uma
solução, e esta solução, representou a utilização da arquitetura do tipo híbrida.
Uma híbrida, mescla das outras duas: cliente-servidor/P2P. Esta
arquitetura utiliza, por exemplo, para transferência de arquivos o P2P e a
arquitetura cliente/servidor para pesquisar quais peers contêm o arquivo
desejado. Uma aplicação muito utilizada neste tipo de arquitetura é a de
mensagem instantânea. O Windows Live Messenger e o aMSN são bons exemplos, onde
usuários podem bater papo online instantaneamente em tempo real. A comunicação
desta aplicação é tipicamente P2P, no entanto, para iniciar uma comunicação, um
usuário registra-se em um servidor, e verifica quem da sua lista de contatos
também está registrado, para a partir de então começar uma comunicação. Essas
aplicações também disponibilizam transferência de arquivos, suporte a grupos,
emoticons, histórico de chat, suporte a conferência, suporte a Proxy, e outras
ferramentas.
Topologias Físicas de Redes
A topologia física pode ser
representada de várias maneiras e descreve por onde os cabos passam e onde as
estações, os nós, roteadores e gateways
estão localizados. As mais utilizadas e conhecidas são as topologias do tipo
estrela, barramento e anel.
Ponto
a Ponto
A topologia ponto a ponto é
a mais simples. Une dois computadores, através de um meio de transmissão
qualquer. Dela pode-se formar novas topologias, incluindo novos nós em sua
estrutura.
Barramento
Esta topologia é bem comum e possui alto
poder de expansão. Nela, todos os nós estão conectados a uma barra que é
compartilhada entre todos os processadores, podendo o controle ser centralizado
ou distribuído. O meio de transmissão usado nesta topologia é o cabo coaxial.
Anel ou Ring
A topologia em anel utiliza
em geral ligações ponto-a-ponto que operam em um único sentido de transmissão.
O sinal circula no anel até chegar ao destino.
Esta topologia é pouco tolerável à falha e possui uma grande limitação quanto a
sua expansão pelo aumento de “retardo de transmissão” (intervalo de tempo entre
o início e chegada do sinal ao nó destino).
Estrela
A topologia em estrela
utiliza um nó central (comutador ou switch) para chavear e gerenciar a
comunicação entre as estações. É esta unidade central que vai determinar a
velocidade de transmissão, como também converter sinais transmitidos por
protocolos diferentes. Neste tipo de topologia é comum acontecer o overhead localizado, já
que uma máquina é acionada por vez, simulando um ponto-a-ponto.
Árvore
A topologia em árvore é
basicamente uma série de barras interconectadas. É equivalente a várias redes
estrelas interligadas entre si através de seus nós centrais. Esta topologia é
muito utilizada na ligação de Hub’s e repetidores.
Estrutura Mista ou Híbrida
A topologia híbrida é bem
complexa e muito utilizada em grandes redes. Nela podemos encontrar uma mistura
de topologias, tais como as de anel, estrela, barra, entre outras, que possuem
como características as ligações ponto a ponto e multiponto.
Grafo (Parcial)
A topologia em garfo é uma mistura de várias
topologias, e cada nó da rede contém uma rota
alternativa que geralmente é usada em situações de falha ou congestionamento.
Traçada por nós, essas rotas têm como função rotear endereços que não pertencem
a sua rede.
Protocolos de Redes
TCP/IP
O TCP/IP é um conjunto de protocolos de
comunicação entre computadores em rede (também chamado de pilha de protocolos
TCP/IP). Seu nome vem de dois protocolos: o TCP
(Transmission Control Protocol - Protocolo de Controlo de Transmissão) e o IP (Internet
Protocol - Protocolo de Interconexão). O conjunto de protocolos pode ser visto
como um modelo de camadas, onde cada camada é responsável por um grupo de
tarefas, fornecendo um conjunto de serviços bem definidos para o protocolo da
camada superior.
As camadas mais altas estão logicamente mais perto do
usuário (chamada camada de aplicação) e lidam com dados mais abstratos,
confiando em protocolos de camadas mais baixas para tarefas de menor nível de
abstração.
|
Protocolos Internet (TCP/IP)
|
|
Camada
|
Protocolo
|
|
|
HTTP, SMTP, FTP, SSH, Telnet, SIP, RDP, IRC, SNMP, NNTP, POP3, IMAP, BitTorrent, DNS, Ping ...
|
|
|
|
|
|
|
|
|
Ethernet, 802.11 WiFi, IEEE 802.1Q, 802.11g, HDLC, Token ring, FDDI, PPP,Switch ,Frame relay,
|
|
|
|
História TCP/IP
O TCP/IP foi desenvolvido em 1969 pelo U.S. Departament of Defense
Advanced Research Projects Agency, como um recurso para um projeto experimental
chamado de ARPANET (Advanced Research Project Agency Network) para preencher a
necessidade de comunicação entre uma grande quantidade de sistemas de
computadores e várias organizações militares dispersas. O objetivo do projeto
era disponibilizar links (vínculos) de comunicação com alta velocidade,
utilizando redes de comutação de pacotes. O protocolo deveria ser capaz de
identificar e encontrar a melhor rota possível entre dois sites(locais), além
de ser capaz de procurar rotas alternativas para chegar ao destino, caso
qualquer uma das rotas tivesse sido destruída. O objetivo principal da
elaboração de TCP/IP foi na época, encontrar um protocolo que pudesse tentar de
todas as formas uma comunicação caso ocorresse uma guerra nuclear.A partir de
1972 o projeto ARPANET começou crescer em uma comunidade internacional e hoje
se transformou no que conhecemos como Internet. Em 1983 ficou definido que
todos os computadores conectados ao ARPANET passariam a utilizar o TCP/IP. No
final dos anos 80 o Fundação nacional de Ciencias em Washington, D.C, começou
construir o NSFNET, um backbone para um supercomputador que serviria para
interconectar diferentes comunidades de pesquisa e também os computadores da
ARPANET. Em 1990 o NSFNET se tornou o backbone principal das redes para a
Internet, padronizando definitivamente o TCP/IP.
IPX/SPX
IPX é um protocolo proprietario da Novell. O IPX opera na camada de rede.
O protocolo Novell IPX/SPX ou Internetwork Packet
Exchange/Sequenced Packet Exchange' é um protocolo proprietário
desenvolvido pela Novell, variante do protocolo "Xerox Network
Systems" (XNS). IPX é o protocolo nativo do Netware - sistema operacional cliente-servidor que fornece aos clientes serviços de compartilhamento de
arquivos, impressão, comunicação, fax, segurança, funções de correio
eletrônico, etc. IPX não é orientado a conexão.
O IPX/SPX tornou-se proeminente durante o início dos anos 80 como uma parte
integrante do Netware, da Novell. O NetWare tornou-se um padrão de facto para o
Sistema Operativo de Rede (SOR), da primeira geração de Redes Locais. A Novell
complementou o seu SOR com um conjunto de aplicações orientada para negócios, e
utilitários para conexão das máquinas cliente.
A diferença principal entre o IPX e o XNS está no uso de diferentes
formatos de encapsulamento Ethernet. A
segunda diferença está no uso pelo IPX do "Service Advertisement
Protocol" (SAP), protocolo
proprietário da Novell.
O endereço IPX completo é composto de 32bits, representado por dígitos
hexadecimais. Por exemplo: AAAAAAAA
00001B1EA1A1 0451 IPX External Node Number Socket Network Number Number
Por sua vez, o SPX ou Sequencial Packet Exchange é um módulo
do NetWare DOS Requester que incrementa o protocolo IPX mediante a supervisão
do envio de dados através da rede. SPX é orientado a conexão e opera na camada de
transporte.
O SPX verifica e reconhece a efetivação da entrega dos pacotes a
qualquer nó da rede pela troca de mensagens de verificação entre os nós de
origem e de destino. A verificação do SPX inclui um valor que é calculado a
partir dos dados antes de transmiti-los e que é recalculado após a recepção,
devendo ser reproduzido exatamente na ausência de erros de transmissão.
O SPX é capaz de supervisionar transmissões de dados compostas por uma
sucessão de pacotes separados. Se um pedido de confirmação não for respondido
dentro de um tempo especificado, o SPX retransmite o pacote envolvido. Se um
número razoável de retransmissões falhar, o SPX assume que a conexão foi
interrompida e avisa o operador.
O protocolo SPX é derivado do protocolo Novell IPX com a utilização do
"Xerox Packet Protocol".
Net BEUI
No início e na terminologia da IBM o protocolo foi chamado NetBIOS. NetBEUI
tem sido trocado pelo TCP/IP nas
redes modernas.
Ao contrário do TCP/IP, o NetBEUI foi concebido para ser usado apenas em
pequenas redes, e por isso acabou tornando-se um protocolo extremamente
simples, que tem um bom desempenho e não precisa de nenhuma configuração
manual, como no TCP/IP. Em compensação, o NetBEUI pode ser usado em redes de no
máximo 255 micros e não é roteável, ou seja, não é permitido interligar duas
redes com ele. É possível manter o NetBIOS activo junto com o TCI/IP ou outros
protocolos, neste caso os clientes tentarão se comunicar usando todos os
protocolos disponíveis.
Apesar de suas limitações, o NetBEUI ainda é bastante usado em pequenas
redes, por ser fácil de instalar e usar, e ser razoavelmente rápido.
FTP
O FTP (File Transfer Protocol -
Protocolo de transferência de arquivos) oferece um meio de transferência e
compartilhamento de arquivos remotos. Entre os seus serviços, o mais comum é o
FTP anônimo, pois permite o download de arquivos contidos em diretórios sem a
necessidade de autenticação. Entretanto, o ace anônimo é restrito a diretórios
públicos que foram especificados pelo administrador da rede.
O protocolo FTP disponibiliza interatividade entre cliente e servidor, de forma
que o cliente possa acessar informações adicionais no servidor, não só ao
próprio arquivo em questão. Como exemplo de facilidadepodemos citar a lista de
arquivos, onde o cliente lista os arquivos existentes no diretório, ou opções
do tipo Help, onde o cliente tem acesso a lista de comandos. Essa
interatividade e proveniente do padrão NVT (Network Virtual Terminal) usado
pelo protocolo TELNET. Contudo, o FTP não permite a negociação de opções,
utilizando apenas as funções básicas do NVT, ou seja, seu padrão default.
O protocolo FTP permite que o cliente especifique o tipo e o formato dos dados
armazenados. Como exemplo, se o arquivo contém texto ou inteiros binários,
sendo que no caso de texto, qual o código utilizado (USASCII, EBCDIC, etc).
Como segurança mínima o protocolo FTP implementa um processo de autenticação e
outro de permissão. A autenticação é verificada através de um código de usuário
e senha, já a permissão, é dada em nível de diretórios e arquivos.
O servidor de FTP possibilita acessos simultâneos para múltiplos clientes. O
servidor aguarda as conexões TCP, sendo que para cada conexão cria um processo
cativo para tratá-la. Diferente de muitos servidores, o processo cativo FTP não
executa todo o processamento necessário para cada conexão. A comunicação FTP
utiliza uma conexão para o controle e uma (ou várias) para transferência de
arquivos.
A primeira conexão (chamada de conexão de
controle "Ftp-control") é utilizada para autenticação e comandos, já
a segunda (chamada de conexão de dados "Ftp-data"), é utilizada para
a transferência de informações e arquivos em questão.
O FTP também é utilizado de forma personalizada e automática em soluções que
trabalham como o EDI (Eletronic Data Interchange), onde Matrizes e Filiais
trocam arquivos de dados com a finalidade de sincronizar seus bancos de dados.
Outro uso seria os LiveUpdates, como o usado nas atualizações dos produtos da
Symantec (Norton Antivírus, Personal Firewall e etc).
Existem também os programas que aceleram download e que utilizam o protocolo
FTP. Esses programas usam tecnologia de múltiplas sessões e empacotamento com a
quebra dos arquivos, conseguindo dessa forma, uma melhora significativa na
velocidade dos downloads.
Os modos de transferência em detalhes:
Padrão
No modo padrão a primeira conexão que é estabelecida pelo cliente é em uma
porta TCP de número alto (varia entre 1024 a 65535, pois é dinâmica) contra o
servidor na porta TCP número 21. Essa conexão é quem autentica e diz ao
servidor qual(is) arquivo(s) o cliente deseja. Esta conexão permite também, a
passagem de outras informações de controle (comandos por exemplo). Contudo,
quando chega à hora de transferir os dados reais uma segunda conexão será
aberta. Diferente da conexão de controle, esta que é de dados, é aberta pelo
servidor em sua porta TCP de número 20 contra o cliente em uma porta TCP de
número alto e que é atribuída também dinamicamente (cliente e servidor negociam
a porta em questão como parte da troca da conexão de controle).
Passivo
No modo passivo a primeira conexão é idêntica ao modo padrão. Contudo, quando
chega à hora de transferir os dados reais, a segunda conexão não opera da mesma
forma que no modo padrão. Ela opera da seguinte forma: o servidor fica
esperando que o cliente abra a conexão de dados. Essa conexão e aberta pelo
cliente em uma porta TCP de número alto (varia entre 1024 a 65535, pois é
dinâmica) contra o servidor em uma porta TCP de número alto também. Tudo fica
estabelecido na conexão de controle inclusive a porta TCP que o cliente vai
usar contra o servidor.
Além de modificar o sentido da
conexão de dados, as portas são altas em ambos os lados. O comando PASV é quem
altera o modo de operação.
Problemas com o protocolo FTP em alguns Gateways
Um aspecto importante que deve ser mencionado é o fato de que as redes
normalmente se conectam à Internet através de um Gateway, e dependendo do tipo
e a concepção dele, poderá fazer com que o FTP seja configurado de forma nada
convencional. Um exemplo é o Proxy da AnalogX. O programa FTP nesse caso deve
ser configurado para conectar diretamente no servidor Proxy, como se este fosse
realmente o servidor de FTP. Entretanto, será passado a ele o endereço do FTP
correto, de tal forma que ele fará o resto do trabalho (conexões no FTP correto
e repasses para o cliente da rede interna que solicitou a conexão).
Advertência sobre
a segurança
Na conexão FTP feita no modo padrão a segunda conexão (ftp-data) traz sérios
problemas para a segurança das redes. O motivo é que a conexão aberta no
sentido do servidor em uma porta TCP de número abaixo de 1024 (o default é 20)
contra o cliente em uma porta TCP numerada de forma dinâmica e maior que 1024,
sem estar com o flag ACK acionado, será considerada pelo administrador da rede
como acesso indevido e os pacotes de dados serão descartados. Já o modo passivo
é considerado o modo correto de abrir uma conexão do tipo "ftp-data".
WAP
WAP (sigla para Wireless Application Protocol; em português,
Protocolo para Aplicações sem Fio) é um padrão internacional para aplicações
que utilizam comunicações de dados digitais sem fio (Internet móvel), como por exemplo o acesso à Internet a
partir de um telefone móvel. WAP foi desenvolvido para prover serviços equivalentes
a um navegador Web com
alguns recursos específicos para serviços móveis. Em seus primeiros anos de
existência, sofreu com a pouca atenção dada pela mídia e tem sido muito
criticado por suas limitações.
Desvantagens
WAP, na época em que foi desenvolvido, pretendia ser a versão do "WWW"
para tecnologias móveis. Entretanto, o que aconteceu foi um distanciamento da
Web HTML / HTTP, o que
deixou os usuários apenas com o conteúdo nativo WAP e Web-to-WAP.
O sistema de tarifação do WAP também
é muito criticado, pois nele os usuários têm de pagar pelos minutos de uso, não
importando o tráfego de dados. Aconteceu o fato de o WAP ter sido superestimado
na época de sua introdução, criando uma expectativa de que atingiria o mesmo
desempenho que o WWW.
O que se viu, porém, foi um serviço
lento, de difícil operação, visualmente pouco atraente e com falhas
operacionais. Este conjunto de problemas acabaram rendendo ao WAP piadas quanto
ao significado real de sua sigla, tais como Worthless Application Protocol
(Protocolo de Aplicações sem Valor) e Wait And Pay (Espere e Pague)
As principais razões que levaram ao fracasso inicial do WAP foram o preço e
suas restrições. Mesmo com o seu barateamento com a introdução do GPRS
(também mais tarde o CDMA2000) e com o enriquecimento de conteúdo graças à abertura à
Internet por parte das operadoras de telefonia móvel, o WAP ainda não descolou,
aquece apenas os motores.
Vantagens
Apesar de tudo, o WAP tem atingido um grande sucesso no Japão.
Enquanto a maior operadora móvel local, a NTT DoCoMo,
claramente deixou de lado o WAP para adotar seu próprio sistema i-mode, as operadoras concorrentes KDDI, (au) e Vodafone
Japan vêm obtendo sucesso com
o WAP. Em particular, serviços como o Sha-Mail da J-Phone e o Java (JSCL), assim como ChakuUta/ChakuMovie (ringtone song/ringtone movie) da au, são baseados em WAP.
Os telefones celulares mais novos já possuem navegadores WAP internos com
suporte para HTML, que permitem até mesmo transferência remota (download)
de figuras estipuladas no código-fonte de uma página de Internet. Ainda mais recentemente, surgiu o Opera Mini, um
navegador WEB/WAP muito mais completo e com ótimo suporte.
Referências
Sistemas
Operacionais - Projeto e Implementação - 2ª Edição - Andrews S. Tanenbaum e
Albert S. Woodhull - http://minix1.woodhull.com - http://www.minix3.org -
http://www.inf.ufrgs.br/~johann/sisop1/minixpage/index.html#toc1 -
http://www.ic.unicamp.br/~islene/2s2007-mo806/slides/Minix.pdf -
http://www.hardware.com.br/artigos/minix/ - http://en.wikipedia.org/wiki/Minix
- http://under-linux.org/lancamento-do-minix-3-1-8-1782/ -
http://www.slideshare.net/PSGALERANI/minixapresent
Principles
of operating systems: design & applications, Brian L, publicação Thompson
Learning, local Boston, Massachusetts ISBN
1-4188-3769-5, Pag. 23
BACH, Maurice J. The design of the Unix operating
system. New Jersey: Prentice Hall, 1990.
TANENBAUM, Andrew. Sistemas operacionais modernos.
Rio de Janeiro: LTC, 1999.
MCKUSICK,
Marshall K.; NEVILLE-NEIL, George V. The design and implementation of the
FreeBSD operating system. Boston: Addison-Wesley, 2004.
BOVET,
Daniel P.; CESATI, Marco. Understanding the Linux kernel. Sebastopol: O'Reilly, 2005.
Bach, M. J. The Design of the
Unix Operating System, Prentice-Hall, 1986.
http://www.intercom.org.br/papers/2002/np10/NP10SOARES.pdf
http://www.cos.ufrj.br/~gabriel/sofix.html
http://www.valoronline.com.br/valoreconomico/materia.asp?id=489857
http://www.mindspring.com/~lfry/part15.htm -
Spread Spectrum Device Compendium
http://informatica.hsw.uol.com.br/lan-switch2.htm
http://pt.wikipedia.org/wiki/Topologia_de_rede
http://www.micropic.com.br/noronha/Informatica/REDES/Redes.pdf
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
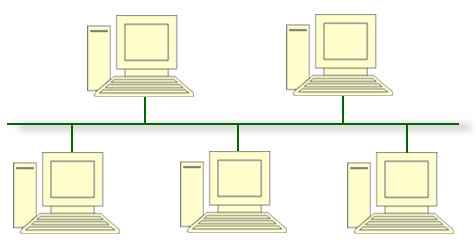{kind=link}
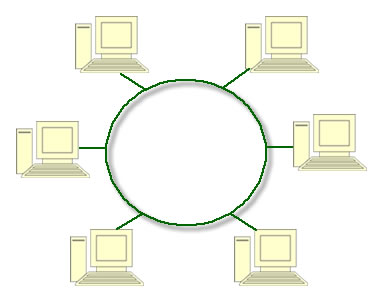{kind=link}
{kind=link}
{kind=link}
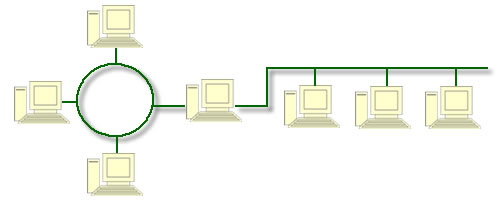{kind=link}
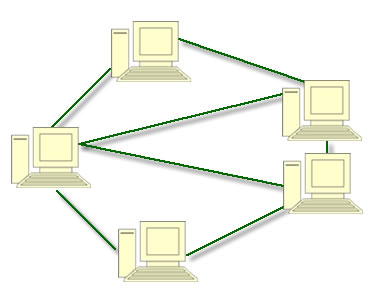{kind=link}